ヒストグラムと正規分布Ⅱ(*・ω・*)b♪ [統計学]
ヒストグラムと正規分布についてのお話その2でございます.....φ(・ω・*)カキカキ
前回お話したとおり、大数の法則と中心極限定理というえら~い人たちが発見した定理によって、n数を増やしていけばどんな事象も正規分布になることが証明されています。
んで標準偏差なんかを使った品質統計のいろいろな分析は正規分布していることが前提で、そうでないデータを使ってやってもそのデータ集団の本来の姿を推測することができないって話なんだけど、それってホントなの?って話ですよね?
そもそも統計的推測はどこまで行っても推測だし、疑いだすとキリがないもんです。(`・ω・´)ノ
でも何の検証もせずにバカ正直に信用しちゃったところで間違っちゃってたらお話になりません。
だってこういう統計を使ってお客さんに「こういうデータ分布になってます。工程能力も十分なんで抜き取り検査で大丈夫です。(*・ω・*)b♪」って説明しといて、いざ不良品が流れたりしたらさぁ大変Σ( ̄□ ̄;)
なので、一度はしっかりと検証してみることが大切です。
と言うことで僕なりに検証してみました(*・ω・*)b♪
まず、前回使ったn4800のデータからランダムに15個、75個、600個と抜き取りヒストグラムを作成していきます。
まずはランダムにデータを方法から.....φ(・ω・*)カキカキ
でも最初にごめんなさいm(__)m 僕のPCのエクセルは古いので最新のを使ってる方は下画像とはコマンドの出し方が違います。
でもやることは一緒なんでご勘弁を( ̄Д ̄)ノ
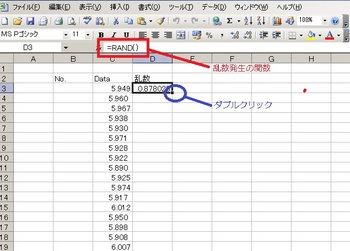
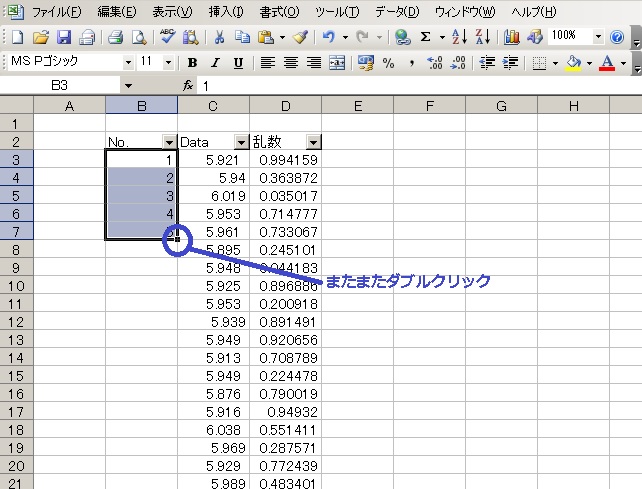
データの隣に乱数(ランダムな数字)を発生させる関数を入れて○の所にマウスポイント(矢印)を持っていきます。矢印が黒色の十字になったらダブルクリック(*・ω・*)b♪
これで全てのデータの隣に乱数が発生します。
お次はオートフィルタ!
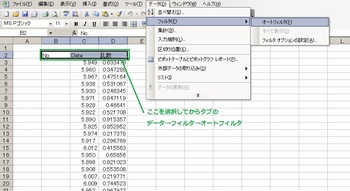
更にオートフィルタで出た▼を乱数の列で選択して
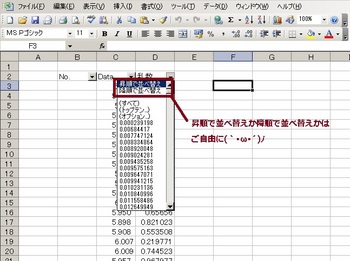
これでデータはランダムに並び替えられました(`・ω・´)ノ
あとはデータ数がわかりやすくなるようデータの隣にナンバリングします。
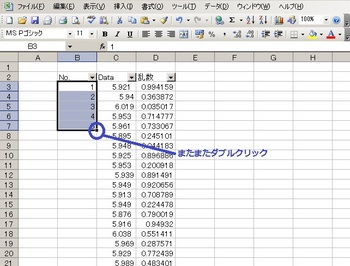
これでデータを抜き取る準備は完了。
あとは必要個数のデータを参照して、前回のやり方でヒストグラムを作成していきます(*`σェ´*)フムフム
ではまず正規分布の見本を見てください
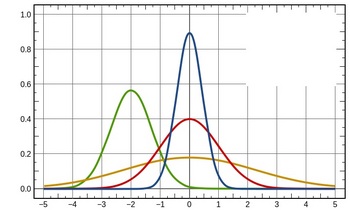
これらはいずれも代表的な正規分布の形です(`・ω・´)ノ
お次はn15のヒストグラム
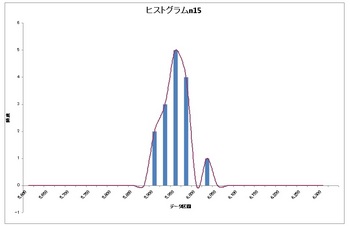
上の正規分布と比べるといびつな形ですね( ̄◇ ̄;)
次はn75!!
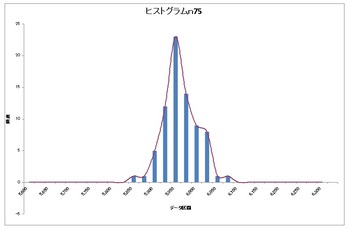
まだちょっと違う(*`σェ´*)
次はぶっ飛んでn600!!!
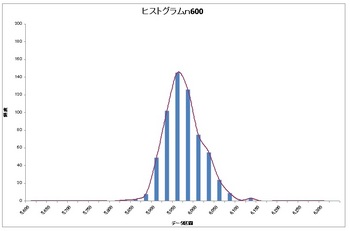
見本にした正規分布の緑と青の中間ってところかな?
ここまでくるとn600では十分正規分布しているといっていいと思います(*・ω・*)b♪
今回は極端な例でn数をぶっ飛ばしてn600としましたが、n75でもまぁまぁ正規分布に近づいていたので実際はn100とか150でいいと思います。
お次はそのあたりを数字で検証してみますね(*・ω・*)b♪
まずヒストグラムを作ったのと同じデータを使ってn数別に標準偏差と工程能力指数を算出して一覧化しました(*`σェ´*)

平均、標準偏差、Cpk、いずれの値もn150を超えるまではnを増やすたびに大きく変化していますが、150以降は変化が緩やかになります。(`・ω・´)ノ
もっとわかりやすくCpkをグラフ化してみましょう(*・ω・*)b♪
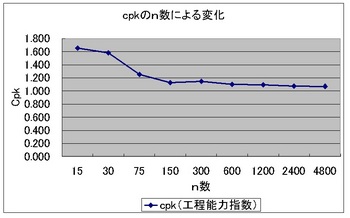
すごく変化してますよね?
ちなみにこのLotの製造総数は4800個。
つまりn4800は全部の製品を検査した真の実力(`・ω・´)ノ
ね?n数を増やすとどんどん真の母集団の値に近づいてますよね?+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
これにて大数の法則と中心極限定理ってものがどんなものかという検証は完了。
(*・ω・*)b♪お疲れ様で~す☆
てかn15とかだとCpkは1.6以上あってほぼ管理不要な超優良工程に見えます。
でもn150だと1.1程度、悪くはないけどちゃんと管理してねってレベルですよね?
そしてn数が150を超えてからの変化は小さく、この程度の数値の変動なら下される判断には大差ないでしょう?(`・ω・´)ノ
n数を多く取るのは面倒です。でもこれを面倒くさがってサボると実力のない工程の改善をほったらかしにしてしまう事になって後でお客さんからクレームを受けたりもっと面倒なことになります。( ̄Д ̄)ノ
初期の評価で手抜きして、後でクレーム食らってお客さんとこで全数選別やって怒られて対策考えて、書類書いて報告して・・・その上ライン保障なんていって賠償請求されてしまったら目も当てられないでしょ??
どう考えたって、初期でn150個検査して分析して、改善後もう一回n150取るほうがまだ楽ですよね?(*・ω・*)b♪
みなさんも機会があれば一度自分の会社でこういうデータを取って自分が普段扱っている数字でこの検証を実践してみてください。
ちなみに工程能力や標準偏差なんて数字をいろいろ使いましたがそれってなんやねんッ( ̄Д ̄)ノ
って人はこちらをご覧ください。
http://yu-noppo.blog.so-net.ne.jp/2013-12-09
http://yu-noppo.blog.so-net.ne.jp/2013-12-12
でわでわ⊂(・∀・)∂))バイバイ
ーーーーーーーーーーーーー
目次へ→
関連記事です(*・ω・*)b♪
・ヒストグラムと正規分布について
・ヒストグラムと正規分布Ⅱ
・正規分布の判断
・標準偏差
・標準偏差のまとめ1
自由度って
・工程能力指数
・工程能力指数と不良率
・Cp、Cpkから不良率算出


前回お話したとおり、大数の法則と中心極限定理というえら~い人たちが発見した定理によって、n数を増やしていけばどんな事象も正規分布になることが証明されています。
んで標準偏差なんかを使った品質統計のいろいろな分析は正規分布していることが前提で、そうでないデータを使ってやってもそのデータ集団の本来の姿を推測することができないって話なんだけど、それってホントなの?って話ですよね?
そもそも統計的推測はどこまで行っても推測だし、疑いだすとキリがないもんです。(`・ω・´)ノ
でも何の検証もせずにバカ正直に信用しちゃったところで間違っちゃってたらお話になりません。
だってこういう統計を使ってお客さんに「こういうデータ分布になってます。工程能力も十分なんで抜き取り検査で大丈夫です。(*・ω・*)b♪」って説明しといて、いざ不良品が流れたりしたらさぁ大変Σ( ̄□ ̄;)
なので、一度はしっかりと検証してみることが大切です。
と言うことで僕なりに検証してみました(*・ω・*)b♪
まず、前回使ったn4800のデータからランダムに15個、75個、600個と抜き取りヒストグラムを作成していきます。
まずはランダムにデータを方法から.....φ(・ω・*)カキカキ
でも最初にごめんなさいm(__)m 僕のPCのエクセルは古いので最新のを使ってる方は下画像とはコマンドの出し方が違います。
でもやることは一緒なんでご勘弁を( ̄Д ̄)ノ
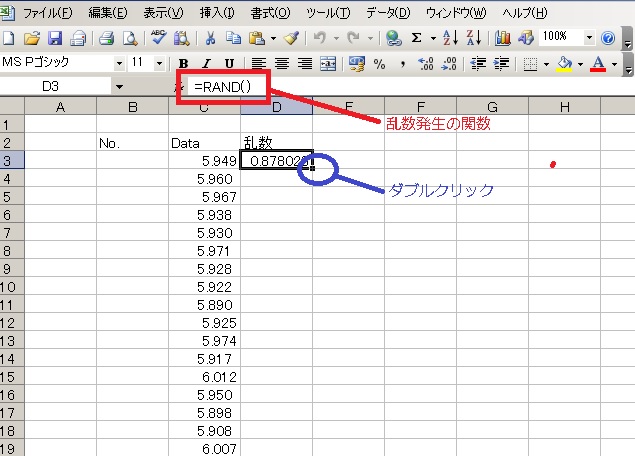
データの隣に乱数(ランダムな数字)を発生させる関数を入れて○の所にマウスポイント(矢印)を持っていきます。矢印が黒色の十字になったらダブルクリック(*・ω・*)b♪
これで全てのデータの隣に乱数が発生します。
お次はオートフィルタ!
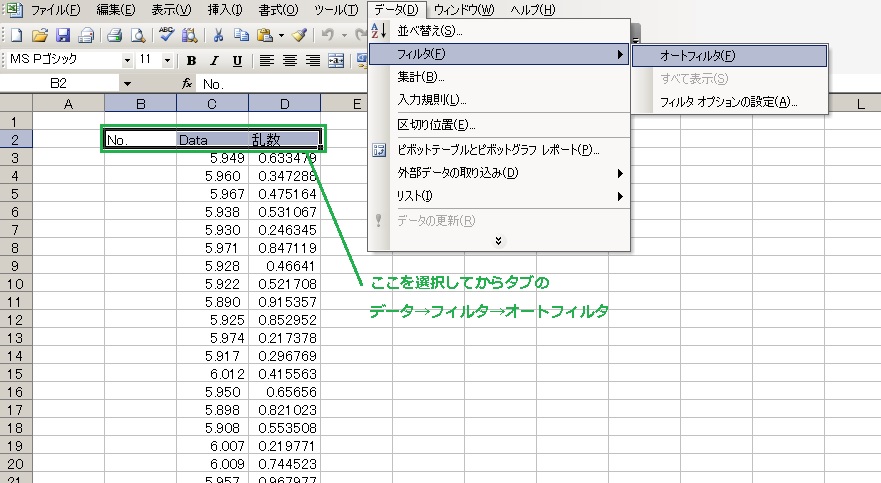
更にオートフィルタで出た▼を乱数の列で選択して
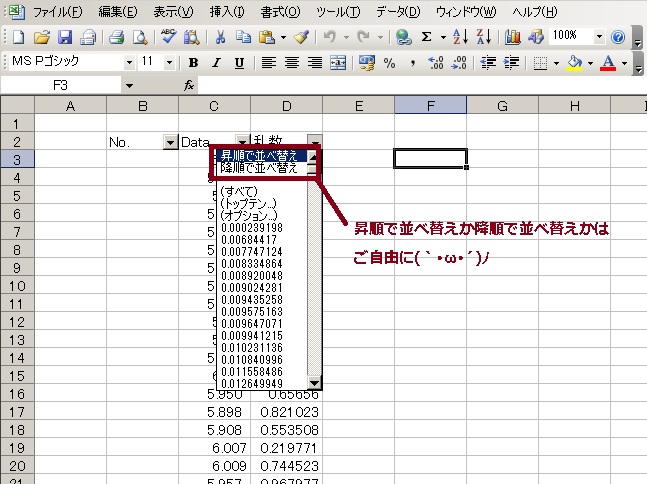
これでデータはランダムに並び替えられました(`・ω・´)ノ
あとはデータ数がわかりやすくなるようデータの隣にナンバリングします。
これでデータを抜き取る準備は完了。
あとは必要個数のデータを参照して、前回のやり方でヒストグラムを作成していきます(*`σェ´*)フムフム
ではまず正規分布の見本を見てください
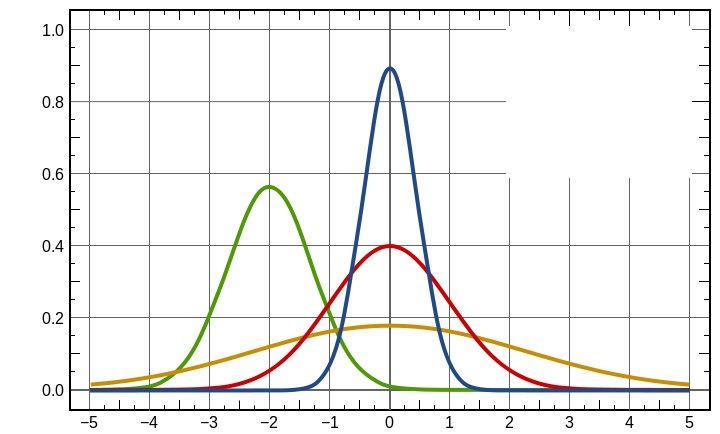
これらはいずれも代表的な正規分布の形です(`・ω・´)ノ
お次はn15のヒストグラム
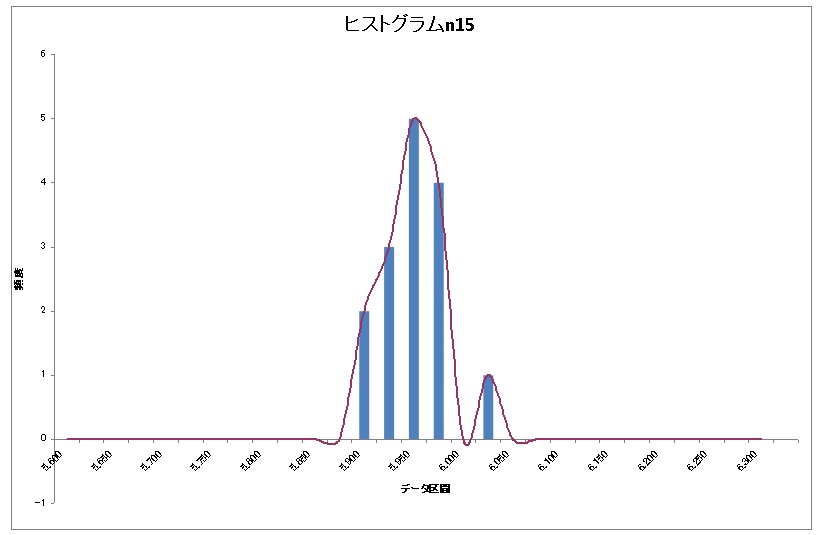
上の正規分布と比べるといびつな形ですね( ̄◇ ̄;)
次はn75!!
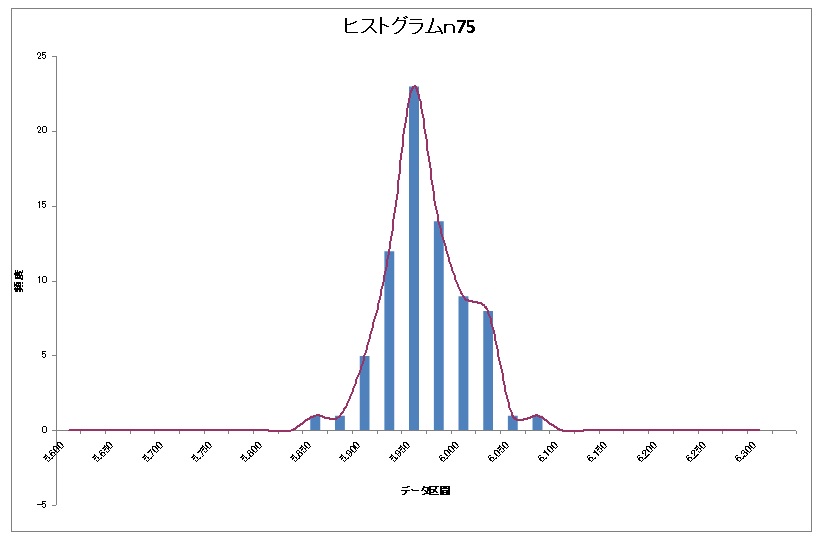
まだちょっと違う(*`σェ´*)
次はぶっ飛んでn600!!!
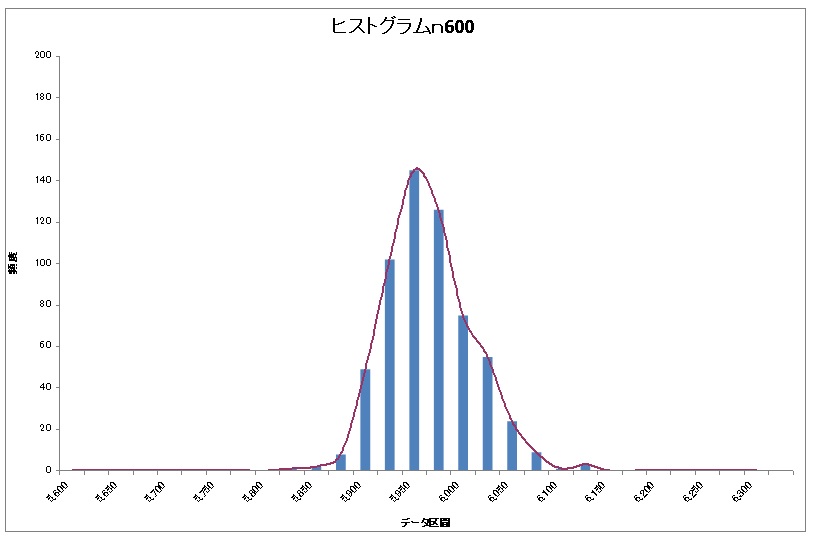
見本にした正規分布の緑と青の中間ってところかな?
ここまでくるとn600では十分正規分布しているといっていいと思います(*・ω・*)b♪
今回は極端な例でn数をぶっ飛ばしてn600としましたが、n75でもまぁまぁ正規分布に近づいていたので実際はn100とか150でいいと思います。
お次はそのあたりを数字で検証してみますね(*・ω・*)b♪
まずヒストグラムを作ったのと同じデータを使ってn数別に標準偏差と工程能力指数を算出して一覧化しました(*`σェ´*)

平均、標準偏差、Cpk、いずれの値もn150を超えるまではnを増やすたびに大きく変化していますが、150以降は変化が緩やかになります。(`・ω・´)ノ
もっとわかりやすくCpkをグラフ化してみましょう(*・ω・*)b♪
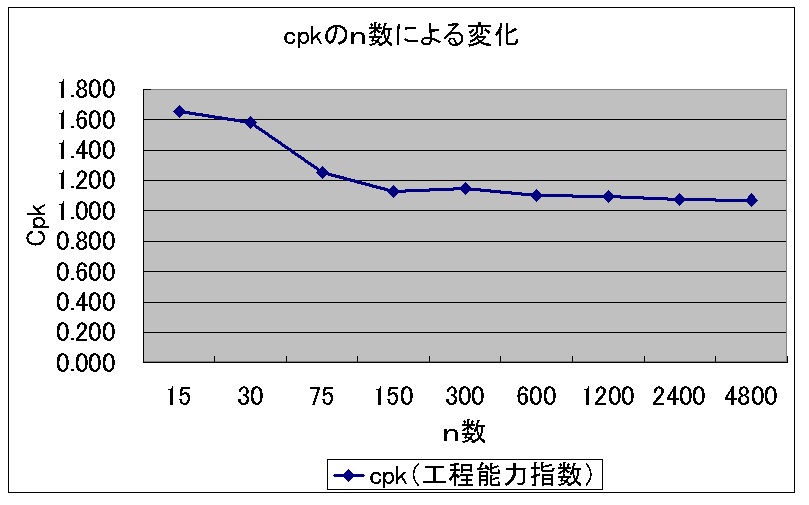
すごく変化してますよね?
ちなみにこのLotの製造総数は4800個。
つまりn4800は全部の製品を検査した真の実力(`・ω・´)ノ
ね?n数を増やすとどんどん真の母集団の値に近づいてますよね?+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
これにて大数の法則と中心極限定理ってものがどんなものかという検証は完了。
(*・ω・*)b♪お疲れ様で~す☆
てかn15とかだとCpkは1.6以上あってほぼ管理不要な超優良工程に見えます。
でもn150だと1.1程度、悪くはないけどちゃんと管理してねってレベルですよね?
そしてn数が150を超えてからの変化は小さく、この程度の数値の変動なら下される判断には大差ないでしょう?(`・ω・´)ノ
n数を多く取るのは面倒です。でもこれを面倒くさがってサボると実力のない工程の改善をほったらかしにしてしまう事になって後でお客さんからクレームを受けたりもっと面倒なことになります。( ̄Д ̄)ノ
初期の評価で手抜きして、後でクレーム食らってお客さんとこで全数選別やって怒られて対策考えて、書類書いて報告して・・・その上ライン保障なんていって賠償請求されてしまったら目も当てられないでしょ??
どう考えたって、初期でn150個検査して分析して、改善後もう一回n150取るほうがまだ楽ですよね?(*・ω・*)b♪
みなさんも機会があれば一度自分の会社でこういうデータを取って自分が普段扱っている数字でこの検証を実践してみてください。
ちなみに工程能力や標準偏差なんて数字をいろいろ使いましたがそれってなんやねんッ( ̄Д ̄)ノ
って人はこちらをご覧ください。
http://yu-noppo.blog.so-net.ne.jp/2013-12-09
http://yu-noppo.blog.so-net.ne.jp/2013-12-12
でわでわ⊂(・∀・)∂))バイバイ
ーーーーーーーーーーーーー
目次へ→
関連記事です(*・ω・*)b♪
・ヒストグラムと正規分布について
・ヒストグラムと正規分布Ⅱ
・正規分布の判断
・標準偏差
・標準偏差のまとめ1
自由度って
・工程能力指数
・工程能力指数と不良率
・Cp、Cpkから不良率算出
- 作者: 牧野 泰江
- 出版社/メーカー: 東京図書
- 発売日: 2003/07
- メディア: 単行本
- 作者: 蓑谷 千凰彦
- 出版社/メーカー: 朝倉書店
- 発売日: 2012/02/29
- メディア: 単行本




コメント 0