Σ式の計算の仕方(`・ω・´)ノ [統計学]
統計の教科書なんかに載ってる公式でよく出てくる「Σ(シグマ大文字)」!
数学を専攻してなかったり得意じゃない人にとっては統計学を敷居の高いものにしてる要因のひとつじゃないでしょうか?(`・ω・´)ノ
なんでそう思うかって?
・・・僕自身がこの記号が意味わかんなくて大っ嫌いだったからです(*`σェ´*)
ほんとにマジで意味わかんねーし、そもそも中学以降数学は図形以外ほぼまともな点数取ったことないしイライラさせられましたね(*`σェ´*)
んで、わかりやすく解説してくれるHPなんかを探しても中々見つからなかった苦汁の経験からこんなブログをいつか書こうと志したわけです(*・ω・*)b♪
ではこのΣですが、実際はこんな記号の意味はおろか計算できなくても全くOKv(。・ω・。)ィェィ♪
正直エクセルさんの関数機能を駆使すれば何の問題もありませんから一切無視したって業務には支障ないでしょう。だって僕らは学者じゃないんですから(*・ω・*)b♪
ただ、「それじゃあ気持ち悪い」「ちゃんと理解しておきたい」って人のために簡単に解説しておきますね(`・ω・´)ノ
ん?なんで無視してOKとか言ってたやつがΣについて語るかって?
だって、後輩とかに教育するときにさらっと解説できた方が、カッコイイですやん?(*`σェ´*)
ただし、元々数学が得意なわけではないので、詳しい人から見たら、僕の説明は少し乱暴だったり違ってたりするかも知れません。その場合はご遠慮なくご指摘ください。m(_ _)m
では本題!
はい、Σは単純に、指定された回数数字を足し合わせなさいという意味です(`・ω・´)ノ
つまりエクセル関数で言うところの”=sum()"と同じ意味で日本語で言う「和」ですね(*・ω・*)b♪
↓これは算術平均・・・つまり一般的に使われる平均の式です↓

この式を言葉にすると、μ(ミュー、つまり平均)はn個あるデータxをiで指示された1個目から順に足し算していき、nで割りなさい問うことになります。
式で書くと・・・・
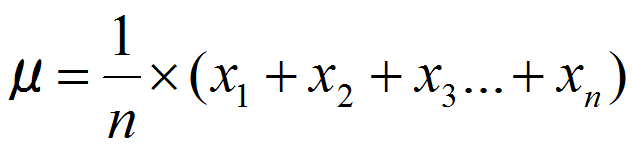
となります。(`・ω・´)ノ
何でそうなるかって?
先ず、最初の公式の1/nのところは一旦無視しますね。
Σとその上下と右側に書かれた記号にはそれぞれ役割があります。
先ずΣは、、、
「あるデータの羅列があったとして、
指定されたデータ番号から順に指定個数のデータを足し算しなさい」と言う意味です。
次にΣの右のxiってのが正にある「データの羅列」です。
そして、iというのが「指定されたデータ番号」となります。
最後に、nが「指定個数」となります。
んで、Σの左前に、1/nがあったので単純にここは掛け算すれば、さっきのような式になるわけです(`・ω・´)ノ
ちなみに、今回説明に用いた記号ですが、文献によっては、iがkだったり、xがaだったり、そもそも平均はμではなくxの上に―を乗っけたエックスバーだったりしますのであしからずm(_ _)m
とまぁ、Σの計算の仕方についてはこんなところです。
知らなくても一切業務には差し支えないけれど、知ってればちょっと自己満足できるかも知れないチョイネタでしたv(。・ω・。)ィェィ♪
------------------------------------------------
目次へ→
------------------------------------------------
製造規格を設定しよう(`・ω・´)ノ [統計学]
製品の寸法なんかは基本的にお客様からの支給や設計者の書いた図面に「規格」として指示されているのが一般的だろうと思います(`・ω・´)ノ
この考え方は僕がモノ作りの師匠から教わったものなので、一般論とマッチするかどうかはわかりませんが、図面に記載された規格を「検査規格」だとします。ものの寸法には必ず、「製造のバラツキ」「測定のバラツキ」・・・など複数のバラツキがあるので、抜き取り検査で単純に規格の上限だと全数検査したときには、NG値が混入しているのではないかと疑うのが普通でしょう(*`σェ´*)
では、抜き取り検査でどの程度の数値であれば、OKといえるのか?
それを「製造規格」として設定し、工程内検査での判断基準とするのが妥当ではないでしょうか(`・ω・´)ノ
では製造規格の計算の仕方についてです(*・ω・*)b♪
①先ずは工程能力指数を求めましょう。
USL〔規格上限〕=10
CL〔規格中心〕=9
LSL〔規格下限〕=8
データ平均値=8.9
標準偏差=0.187
だったとします。 このとき、工程能力指数Cpkは・・・
なのでエクセルで求めるとすると、、、
となり、Cpk=1.604と出ました。
長優秀ですね(*・ω・*)b♪
→Cpkのところがよくわからない人は目次から工程能力指数に関していくつかの記事を参照してください。 ―目次です。-
②次に求められたCpkがどの程度まで低下しても許容できるかを検討しましょう(`・ω・´)ノ
求められた工程能力指数Cpkは1.604ととても優秀でした。
一般論では1.33~1.67が十分な能力と言われていますし、お客様との品質の取り交わしで、
AQLなどを決めている場合、仮にAQL0.3%以下の場合、Cpk1.0がこのAQL0.3%の境界線になります。
ここでは、例として1.33としましょう。
③②で許容できるCpkを1.33と決めたので、①の式のCpkのとこに1.33を代入して、
標準偏差を?としてみましょう(`・ω・´)ノ
平均値は規格中心より下限側にあったので、公式の後ろ半分、(平均-LSL・・・の部分だけ考えればOK♪
そうすると、、、

となり、これを計算していくと、
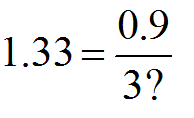
最後に、、、
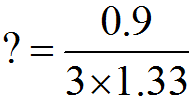
となります。つまり ?とした標準偏差は0.226となります(`・ω・´)ノ
④③で得たCpk1.33のときの標準偏差から平均値±3σを計算しようv(。・ω・。)ィェィ♪
これは単純、初期評価で得られた平均値8.9に③で得た標準偏差×3を足し引きして、
データの分布範囲を推測します。
そうすると、、、

となり、この+3σが製造規格の上限、-3σが下限となります。(`・ω・´)ノ
この規格から外れると言うことは、②で検討した工程能力指数を下回っている可能性があると言うことで何らかの処置を講じる必要があると言うことになりますが、Cpkの部分を1.33など高い数値にしおいたり、お客様との取り交わしの範疇に設定しておくことで、あくまで社内的な処置だけで納めることが可能となり、外部に迷惑を掛けたりすることなく、早期に処理を図れるようになると言うことですv(。・ω・。)ィェィ♪
これにて僕なり(師匠の受け売り)の製造規格の算出と設定は完了ドモヽ(´Д` ) ( ´Д`)ノドモ
役に立ちそうでしたら是非みなさんの現場でも実践してみてくださいm(_ _)m
でわでわ本日はこれにて⊂(・∀・)∂))バイバイ
-----------------------------------------------------
目次へ→
-----------------------------------------------------
相関ってなんだ?|д・) ソォーッ… [統計学]
今日、相関について書いてみますv(。・ω・。)ィェィ♪
製造工程の初期の作りこみなんかやってると「パラメータAと製品寸法Bには相関関係はあるの?」とか聞かれたことありませんか?
そもそも相関てなんやねん!(*`σェ´*)
参考書によってはQC七つ道具の中の散布図として紹介されています。
二つの数値化できる関係性がありそうな事柄の因果関係の有無を確認することができます(`・ω・´)ノ
ではさっそく・・・
☆解説☆
丸い鉄の棒を刃物で削る設備をイメージしてください。
刃物の位置は手元のダイヤルで操作でき、初期位置は0、ひと目盛りづつダイヤルを回していったときの鉄の棒の外径の変化との関係性を追いかけて見ましょう(`・ω・´)ノ
↓こんなデータになったとします↓
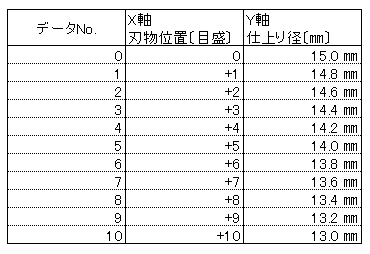
まぁ単純にひと目盛り0.2㎜変化してるのはわかりやすくするためなのでツッコミはご勘弁を・・・(`_´)ゞ
ではこれを散布図にしてみましょう!↓↓
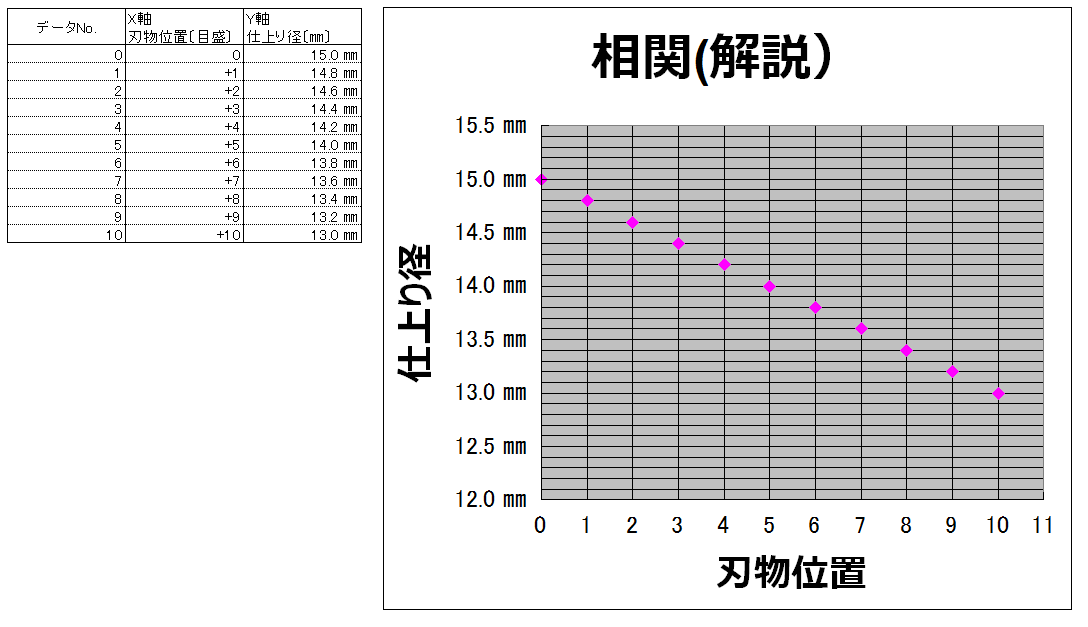
はい、右下がり一直線のプロットになりますね(`・ω・´)ノ
このグラフをもう少し詳しく見てみると・・・↓↓
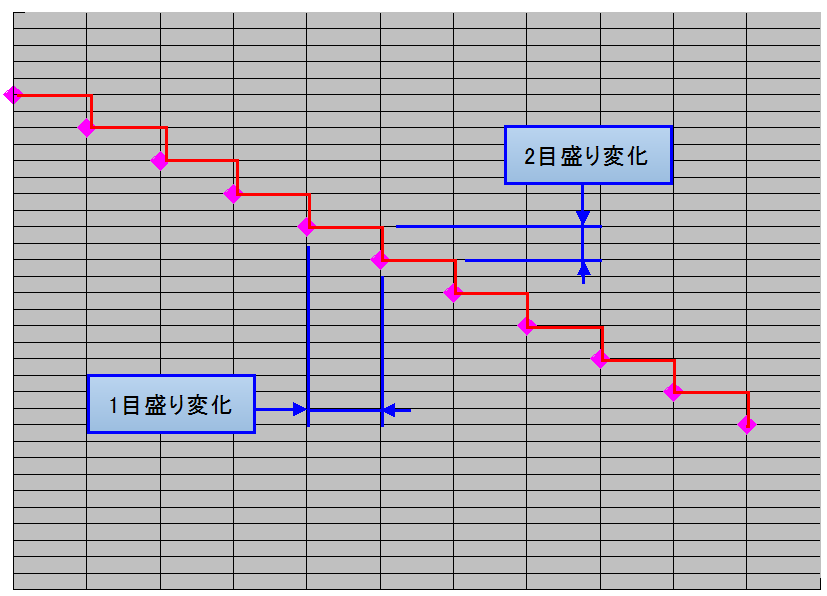
ジャジャン♪(*・ω・*)b♪
横にひと目盛り、下にふた目盛りのピッチで右下がりになってますね(`・ω・´)ノ
これは小学校で習った反比例というやつですね(*・ω・*)b♪
そう、相関とは単純には比例や反比例といったような関係性を調べる方法なんですv(。・ω・。)ィェィ♪
残念ながら、どういう比率で比例しているかなんかは別の計算になりますが、関係性の強さを簡単に見ることができる方法なんですね(*・ω・*)b♪
ちなみに関係性の強さの見分け方としては、正方形のグラフを作ります。
そこに解説のグラフのようにデータをプロットしたあと、エクセルの近似曲線の線形近似を追加して下さい。
引かれた線形近似の角度が正方形の中で45度に近いほど強い相関関係があるということ。
逆に0度・180度に近いほど相関関係は弱い(つまり2つの数値は関係し合っていない)ということになります(`・ω・´)ノ
☆注意点☆
でも実際相関分析を使う現場では先ほどの解説のようにひとつづつパラメータを振るなんてやってられない場合もあるし、データにはバラツキもあります。当然、注意しなければならないことがあります(`・ω・´)ノ
↓こちらは悪い例です↓
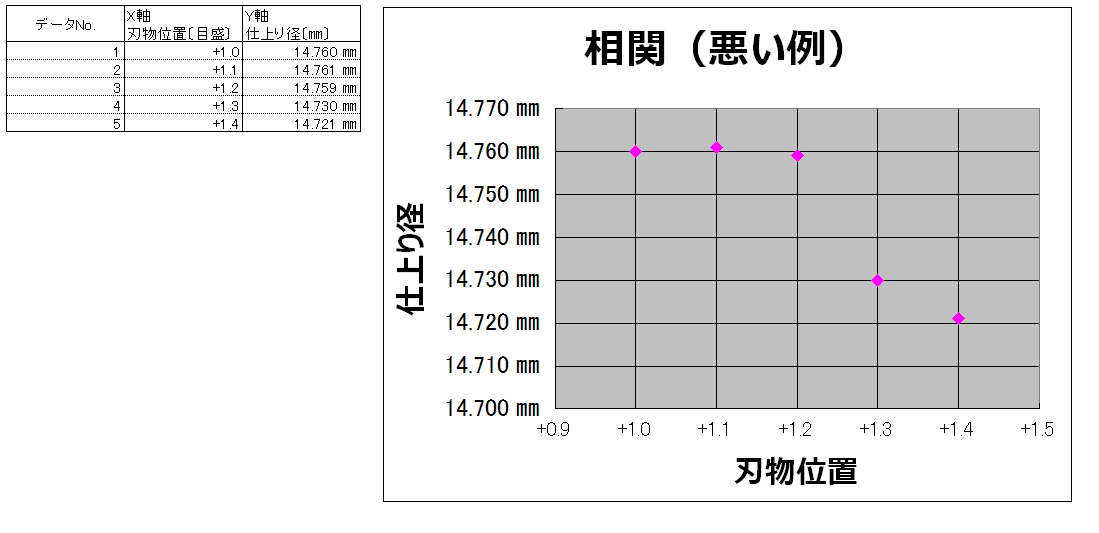
何が駄目かというと・・・・
①制御できる精度が0.1㎜程度または未知数なのにパラメータの振り幅が小さすぎる。
②n数が少なすぎる。
お次は良い例(`・ω・´)ノ
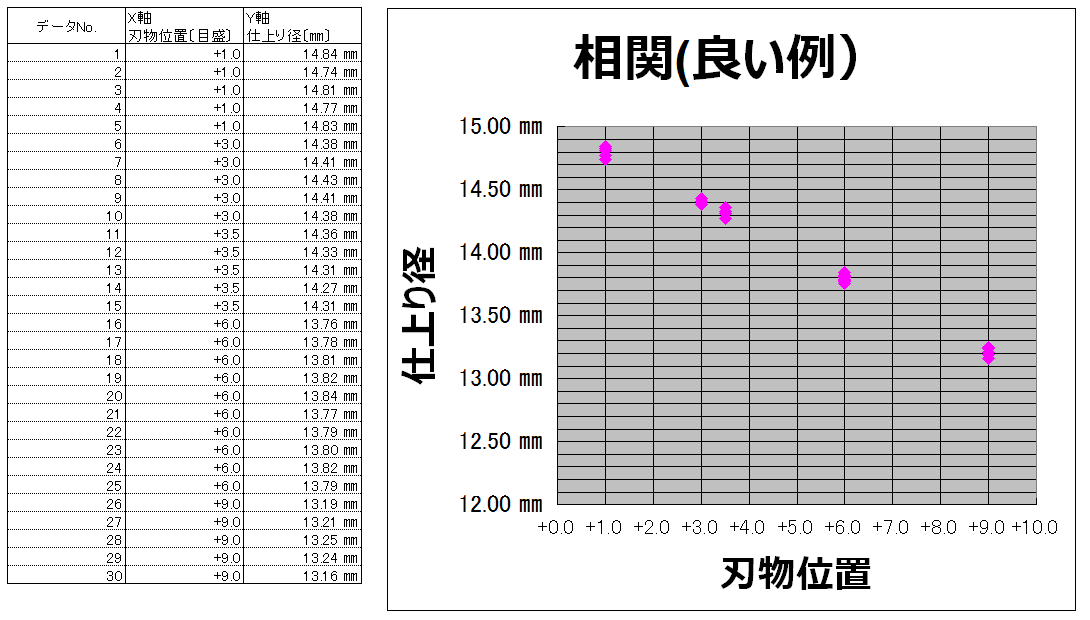
大事なことは・・・
①同じパラメータで複数個データを取りましょう。
②振り幅を大きめにしましょう。
僕は検査レベルの相関を取るときなんかは規格外の製品のデータなんかも含めてました。
要は、0.1㎜は平気でバラツキがあるような設備を使って、0.1㎜分のパラメータ振りをやったって、変化はバラツキに飲まれて、関係性なんか見極めれる訳ないんですよね(`・ω・´)ノ
ちなみにグラフにしたとき、右肩下がりなのは「負の相関関係がある」といいます。
逆に右肩上がりだと「正の相関がある」ということです(*・ω・*)b♪
さらに「いちいち散布図作るのメンドクセーッ!Σ( ̄□ ̄;)」ってひとはエクセル関数で「=CORREL(データX軸、データY軸)」を使えば相関係数という数値で判断することができますv(。・ω・。)ィェィ♪
相関係数の一般論は・・・
1.0≧|R|≧0.7 :高い相関がある
0.7≧|R|≧0.5 :かなり高い相関がある
0.5≧|R|≧0.4 :中程度の相関がある
0.4≧|R|≧0.3 :ある程度の相関がある
0.3≧|R|≧0.2 :弱い相関がある
0.2≧|R|≧0.0 :ほとんど相関がない
※R=相関係数、+=正の相関、-=負の相関
となっています(`・ω・´)ノ
さてさて、相関については大体こんな所です。
みなさんのお仕事に役立てていただければ幸いです。
それでは本日はこれにて!⊂(・∀・)∂))バイバイ
--------------------------------------------------------
目次へ→
--------------------------------------------------------
工程能力指数(*`σェ´*) [統計学]
さて、今日は工程能力指数についてのお話を少し詳しく(`・ω・´)ノ
品質管理や品質保証をやる人なら耳にしたことある言葉ですよね?
要はその工程の製造精度が規格に対してどの程度の実力を持っているか?という数字.....φ(・ω・*)
CpとCpkがあります(*・ω・*)b♪
まずはどんなものかってイメージが大切ということで・・・
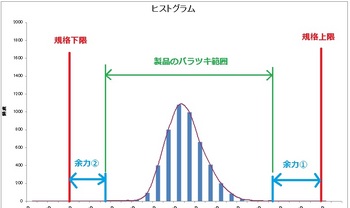
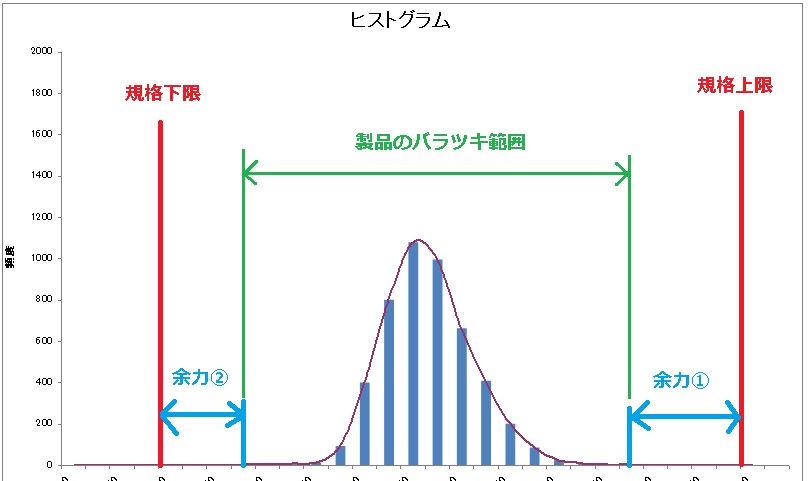
あるデータのヒストグラムです。
ヒストグラムが何なのかについてはこちら↓をご覧ください。
赤線が規格の上限と下限、それに対し緑線が工程のバラツキ範囲。
そして水色線がバラツキ範囲と規格線の隙間・・・つまり余力です(*・ω・*)b♪
当然この隙間が大きいほど不良が発生しにくいということは感覚的にわかることですが、じゃあそこんとこ完全に信用していい隙間の広さってどのくらいなの?このデータからみてこの程度隙間あいてるのは良しとしていいレベルなの??
ってところを数値化したのが工程能力指数です(*・ω・*)b♪
Cpとは規格の幅を製品のバラツキの幅で割り返したものです(`・ω・´)ノ
製品のバラツキの幅は6σ・・・つまり標準偏差の6倍です。
エクセルでの標準偏差の計算式は「=STDEV(セル:セル)」です。
つまりσ=STDEV(セル:セル)を求め、
Cp=(規格上限-規格下限)/(6*σ) という式になります。
ちなみに文献では規格上限を「USL」、下限を「LSL」と表記しているものもあります.....φ(・ω・*)カキカキ
これで得られた値がバラツキから見た隙間の広さを数値化したものです。
数値が大きければ大きいほど優秀ってことですね(`・ω・´)ノ
んでCpはわかったけどCpkって??ってところですが、もう一度このグラフを見てくださいv(。・ω・。)ィェィ♪
ちょっとわかりにくいですが、青線の余力①と余力②の広さは全く同じでしょうか??
そうです、余力②の方がちょっと狭いんですよね?
製造現場において、製品寸法の平均値が規格の真ん中にどんぴしゃで重なっていることなんてまずありえなくて、常に上限か下限のどちらかにわずかでもシフトしているはず(`・ω・´)ノ
Cpの計算は単に規格の広さ÷バラツキ範囲の広さという計算をしているだけでこのことを全く加味していないんですΣ(°□°)⊃------マジッ
Cpkはこれを加味しているんですね。
計算式は・・・
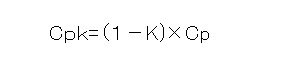
ここで出てくる「K」は偏り係数・・・つまり規格の真ん中から平均値がずれていることを前提にそのズレを算出する値です( ̄Д ̄)ノ
そのKをまず算出する必要があるので計算式を・・・
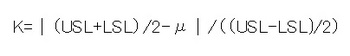
・・・はい、意味わかりません(´∀`*)ウフフ
僕中学校以降、大学まで一番嫌いな科目は数学でした☆
なのでこんな式意味わかりません状態でした。こんな計算式クソ食らえです(*^ワ^*)
でも必要なことだから必死に解こうとしてたんですがね、調べて句とエクセルでこれを簡単に算出する方法を知りましたv(。・ω・。)ィェィ♪
それがこちら↓
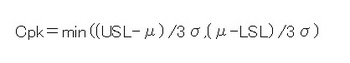
ここで出てくる「μ」という記号は平均値のことです。
なのであらかじめ、平均を算出しておきましょう。エクセルでの計算式は「=AVERAGE(セル:セル)」ですね(`・ω・´)ノ
んで上の公式の=から右側をμのところだけ平均値に変えてそのまま入力してもらえればCpkが算出されます(*・ω・*)b♪
ちなみに「=Min( , )」もエクセルの計算式のひとつ。
なにを計算しているかというと・・・
1、、、(規格上限-平均値)/(3*σ)
2、、、(平均値-規格下限)/(3*σ)
を求めて1と2のより小さい方・・・つまり上下それぞれの規格線に対し、より小さい隙間がどっちかを見て算出しているんです。
σに掛ける数値が6じゃなくて3なのも、バラツキの平均値を中心にそれぞれ規格上限までと規格下限までの距離を別々に見に行ってるから・・・全体だと6σ、半分だと3σって話ですね(*`σェ´*)フムフム
さてこんな感じでCpkってのは現実としてデータの平均値は規格の中心とイコールではないという前提で真の実力を見に行ってる数値ということです(`・ω・´)ノ
じゃあCpってあんまり使えない数値なんだね( ̄Д ̄)ノ
ってお話ではありませんよ?CpもCpkもどちらも大切です。
まぁ簡単にいうと
Cpkというのは加工狙い値などのチューニング誤差まで含んだ現実的な実力値(`・ω・´)ノ
Cpというのは仮に加工狙い値と規格中心が重なるまでチューニングすればここまでの実力を発揮できるという値(*・ω・*)b♪
だと僕は解釈しています(*`σェ´*)フムフム
つまり、まずCpをみて工程能力指数が根本的に足りるかどうかを判断!
ここで足りなきゃ即改善!足りてりゃCpkを見る!!
Cpkだけが足りないならチューニングだけで何とかなるかも知れないってことですv(。・ω・。)ィェィ♪
ちなみに工程能力指数がいくらだったらどうなのってお話ですがその判断基準は一般的に・・・
Cp(またはCpk)≧1.67・・・十分すぎる能力。
バラツキが多少大きくなっても心配なく、
管理の簡素化を検討してもよいレベル。
1.67>Cp(Cpk)≧1.33・・・十分な能力。
この状態を維持するべき。
1.33>Cp(Cpk)≧1.00・・・十分とはいえないがまずまず。
1.00に近づくと不良発生の可能性があるので、
しっかり管理し、必要に応じて処置する。
1.00>Cp(Cpk)≧0.67・・・能力不足。
不良品が発生していることが予想される。
全数検査による製品の選別と改善処置が必要。
0.67>Cp(Cpk)・・・・・・・・工程能力が非常に不足している。
品質を満足できる状態ではなく、原因の究明と改善対策を
緊急的に行う必要がある。
または規格の再検討を行う。
ということです(*`σェ´*)フムフム
さて、普段抜取検査だけで管理している工程はありませんか?
一度n数を集めてCp・Cpkを算出されてはいかがでしょうか?
PS
工程能力指数もデータが正規分布に帰属することを前提としています(`・ω・´)ノ
なのでヒストグラムや歪度や尖度の確認もしっかり行ってください。
それでは本日もお付き合いいただきありがとうございました⊂(・∀・)∂))バイバイ
------------------------------------
目次へ→
------------------------------------
品質管理や品質保証をやる人なら耳にしたことある言葉ですよね?
要はその工程の製造精度が規格に対してどの程度の実力を持っているか?という数字.....φ(・ω・*)
CpとCpkがあります(*・ω・*)b♪
まずはどんなものかってイメージが大切ということで・・・
あるデータのヒストグラムです。
ヒストグラムが何なのかについてはこちら↓をご覧ください。
赤線が規格の上限と下限、それに対し緑線が工程のバラツキ範囲。
そして水色線がバラツキ範囲と規格線の隙間・・・つまり余力です(*・ω・*)b♪
当然この隙間が大きいほど不良が発生しにくいということは感覚的にわかることですが、じゃあそこんとこ完全に信用していい隙間の広さってどのくらいなの?このデータからみてこの程度隙間あいてるのは良しとしていいレベルなの??
ってところを数値化したのが工程能力指数です(*・ω・*)b♪
Cpとは規格の幅を製品のバラツキの幅で割り返したものです(`・ω・´)ノ
製品のバラツキの幅は6σ・・・つまり標準偏差の6倍です。
エクセルでの標準偏差の計算式は「=STDEV(セル:セル)」です。
つまりσ=STDEV(セル:セル)を求め、
Cp=(規格上限-規格下限)/(6*σ) という式になります。
ちなみに文献では規格上限を「USL」、下限を「LSL」と表記しているものもあります.....φ(・ω・*)カキカキ
これで得られた値がバラツキから見た隙間の広さを数値化したものです。
数値が大きければ大きいほど優秀ってことですね(`・ω・´)ノ
んでCpはわかったけどCpkって??ってところですが、もう一度このグラフを見てくださいv(。・ω・。)ィェィ♪
ちょっとわかりにくいですが、青線の余力①と余力②の広さは全く同じでしょうか??
そうです、余力②の方がちょっと狭いんですよね?
製造現場において、製品寸法の平均値が規格の真ん中にどんぴしゃで重なっていることなんてまずありえなくて、常に上限か下限のどちらかにわずかでもシフトしているはず(`・ω・´)ノ
Cpの計算は単に規格の広さ÷バラツキ範囲の広さという計算をしているだけでこのことを全く加味していないんですΣ(°□°)⊃------マジッ
Cpkはこれを加味しているんですね。
計算式は・・・
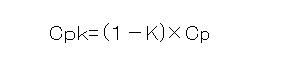
ここで出てくる「K」は偏り係数・・・つまり規格の真ん中から平均値がずれていることを前提にそのズレを算出する値です( ̄Д ̄)ノ
そのKをまず算出する必要があるので計算式を・・・
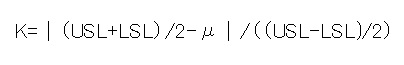
・・・はい、意味わかりません(´∀`*)ウフフ
僕中学校以降、大学まで一番嫌いな科目は数学でした☆
なのでこんな式意味わかりません状態でした。こんな計算式クソ食らえです(*^ワ^*)
でも必要なことだから必死に解こうとしてたんですがね、調べて句とエクセルでこれを簡単に算出する方法を知りましたv(。・ω・。)ィェィ♪
それがこちら↓
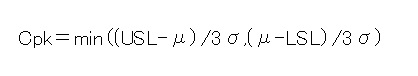
ここで出てくる「μ」という記号は平均値のことです。
なのであらかじめ、平均を算出しておきましょう。エクセルでの計算式は「=AVERAGE(セル:セル)」ですね(`・ω・´)ノ
んで上の公式の=から右側をμのところだけ平均値に変えてそのまま入力してもらえればCpkが算出されます(*・ω・*)b♪
ちなみに「=Min( , )」もエクセルの計算式のひとつ。
なにを計算しているかというと・・・
1、、、(規格上限-平均値)/(3*σ)
2、、、(平均値-規格下限)/(3*σ)
を求めて1と2のより小さい方・・・つまり上下それぞれの規格線に対し、より小さい隙間がどっちかを見て算出しているんです。
σに掛ける数値が6じゃなくて3なのも、バラツキの平均値を中心にそれぞれ規格上限までと規格下限までの距離を別々に見に行ってるから・・・全体だと6σ、半分だと3σって話ですね(*`σェ´*)フムフム
さてこんな感じでCpkってのは現実としてデータの平均値は規格の中心とイコールではないという前提で真の実力を見に行ってる数値ということです(`・ω・´)ノ
じゃあCpってあんまり使えない数値なんだね( ̄Д ̄)ノ
ってお話ではありませんよ?CpもCpkもどちらも大切です。
まぁ簡単にいうと
Cpkというのは加工狙い値などのチューニング誤差まで含んだ現実的な実力値(`・ω・´)ノ
Cpというのは仮に加工狙い値と規格中心が重なるまでチューニングすればここまでの実力を発揮できるという値(*・ω・*)b♪
だと僕は解釈しています(*`σェ´*)フムフム
つまり、まずCpをみて工程能力指数が根本的に足りるかどうかを判断!
ここで足りなきゃ即改善!足りてりゃCpkを見る!!
Cpkだけが足りないならチューニングだけで何とかなるかも知れないってことですv(。・ω・。)ィェィ♪
ちなみに工程能力指数がいくらだったらどうなのってお話ですがその判断基準は一般的に・・・
Cp(またはCpk)≧1.67・・・十分すぎる能力。
バラツキが多少大きくなっても心配なく、
管理の簡素化を検討してもよいレベル。
1.67>Cp(Cpk)≧1.33・・・十分な能力。
この状態を維持するべき。
1.33>Cp(Cpk)≧1.00・・・十分とはいえないがまずまず。
1.00に近づくと不良発生の可能性があるので、
しっかり管理し、必要に応じて処置する。
1.00>Cp(Cpk)≧0.67・・・能力不足。
不良品が発生していることが予想される。
全数検査による製品の選別と改善処置が必要。
0.67>Cp(Cpk)・・・・・・・・工程能力が非常に不足している。
品質を満足できる状態ではなく、原因の究明と改善対策を
緊急的に行う必要がある。
または規格の再検討を行う。
ということです(*`σェ´*)フムフム
さて、普段抜取検査だけで管理している工程はありませんか?
一度n数を集めてCp・Cpkを算出されてはいかがでしょうか?
PS
工程能力指数もデータが正規分布に帰属することを前提としています(`・ω・´)ノ
なのでヒストグラムや歪度や尖度の確認もしっかり行ってください。
それでは本日もお付き合いいただきありがとうございました⊂(・∀・)∂))バイバイ
------------------------------------
目次へ→
------------------------------------
正規分布の判断.....φ(・ω・*)カキカキ [統計学]
ずいぶんまえですが、正規分布について参考データなんかをつけて書いたことがあったと思いますが、今日はその補足をしてみようと思います。(`・ω・´)ノ
品質統計で使う色んな計算値の多くはデータが正規分布していることが前提でした(*`σェ´*)フムフム
じゃあ集めたデータが正規分布かどうかを判断するのはどうすりゃいいのよ?ってお話です。
といっても思いつきで書くのでデータなんかは準備してません( p′︵‵。)
なので簡単に説明します。(`・ω・´)ノ
方法は大きく3つ!!
その1
帰無仮説:このデータは正規分布である
対立仮説:このデータは正規分布ではない
という仮説をたて、正規性の検定を行う方法!!でもこれは中々専門的です。簡単にやるためのソフトなんかもある様ですが、僕的にもちょっと敷居が高い感じ(;´Д`)
その2
ヒストグラムを作成し、視覚的に正規分布と同じ形をしているかを確認する!
この間書いたのはこれですね(`・ω・´)ノ
気になる方はこちらをご覧ください↓↓
http://yu-noppo.blog.so-net.ne.jp/2014-01-13
でもこれだけじゃ感覚的すぎない?って人!
その3!
歪度(わいど)と尖度(せんど)を調べましょう(`・ω・´)ノ
歪度とは分布のゆがみを表す数字(。・Д・)ゞ分布の形が左右均等であれば0になります。
尖度は分布の峰(ヒストグラムのてっぺん)のとんがり具合を表す数値。
正規分布の形にもよるでしょうが、標準正規分布の尖度=3です。
ただし、両方ドンピシャな数字になることなんて珍しいでしょう。
なので、この2つの数字だけで判断すると落とし穴にハマります(`・ω・´)ノ
何って?
二山型の分布になって左右均等でも歪度は0となります。(。・Д・)ゞ
このとき正規分布と言えるのか?いえません(;´Д`)
じゃあどうすんの??
その2とその3をミックスしちゃえばいいんです(`・ω・´)ノ
視覚的にある程度正規分布に近いことを確認し、歪度と尖度で自分の判断を確信させるんです(*`σェ´*)
ちなみに僕は歪度0,2〜0,4くらいならOKと判断してます(`・ω・´)ノ
いやn数増やし続ければいずれ限りなく0に近づくのは確認したんですが、0.4の時もほぼ0の時も、得られた工程能力とかの数値の変化はホント微細なもんでしたので・・・|д・) ソォーッ…
まぁこれもどんな状況のデータをどんな精度で保証したいのかって事によると思うので一概には言えませんが・・・(。・Д・)ゞ
ということで久々の統計学ネタでございました。
本日もお付き合い頂きありがとうございます(ノシ=´ω`=)ノシ
-------------------------------------
目次へ→
------------------------------------
品質統計で使う色んな計算値の多くはデータが正規分布していることが前提でした(*`σェ´*)フムフム
じゃあ集めたデータが正規分布かどうかを判断するのはどうすりゃいいのよ?ってお話です。
といっても思いつきで書くのでデータなんかは準備してません( p′︵‵。)
なので簡単に説明します。(`・ω・´)ノ
方法は大きく3つ!!
その1
帰無仮説:このデータは正規分布である
対立仮説:このデータは正規分布ではない
という仮説をたて、正規性の検定を行う方法!!でもこれは中々専門的です。簡単にやるためのソフトなんかもある様ですが、僕的にもちょっと敷居が高い感じ(;´Д`)
その2
ヒストグラムを作成し、視覚的に正規分布と同じ形をしているかを確認する!
この間書いたのはこれですね(`・ω・´)ノ
気になる方はこちらをご覧ください↓↓
http://yu-noppo.blog.so-net.ne.jp/2014-01-13
でもこれだけじゃ感覚的すぎない?って人!
その3!
歪度(わいど)と尖度(せんど)を調べましょう(`・ω・´)ノ
歪度とは分布のゆがみを表す数字(。・Д・)ゞ分布の形が左右均等であれば0になります。
尖度は分布の峰(ヒストグラムのてっぺん)のとんがり具合を表す数値。
正規分布の形にもよるでしょうが、標準正規分布の尖度=3です。
ただし、両方ドンピシャな数字になることなんて珍しいでしょう。
なので、この2つの数字だけで判断すると落とし穴にハマります(`・ω・´)ノ
何って?
二山型の分布になって左右均等でも歪度は0となります。(。・Д・)ゞ
このとき正規分布と言えるのか?いえません(;´Д`)
じゃあどうすんの??
その2とその3をミックスしちゃえばいいんです(`・ω・´)ノ
視覚的にある程度正規分布に近いことを確認し、歪度と尖度で自分の判断を確信させるんです(*`σェ´*)
ちなみに僕は歪度0,2〜0,4くらいならOKと判断してます(`・ω・´)ノ
いやn数増やし続ければいずれ限りなく0に近づくのは確認したんですが、0.4の時もほぼ0の時も、得られた工程能力とかの数値の変化はホント微細なもんでしたので・・・|д・) ソォーッ…
まぁこれもどんな状況のデータをどんな精度で保証したいのかって事によると思うので一概には言えませんが・・・(。・Д・)ゞ
ということで久々の統計学ネタでございました。
本日もお付き合い頂きありがとうございます(ノシ=´ω`=)ノシ
-------------------------------------
目次へ→
------------------------------------
データ収集って(*`σェ´*)フムフム [統計学]
久々に統計学について書いてみます( ̄Д ̄)ノ
もともと、統計学の復習なんかから始まったこのブログも僕の意志の弱さから方向性を失いかけていますので、久々に路線を戻そうと思います ドモヽ(´Д` ) ( ´Д`)ノドモ
じゃあ何の話すんの?ってとこなんですが、端的、ミクロ的に言えばデータ収集の注意事項(`・ω・´)ノ
対極的、マクロ的に言えば統計的原則と組織活動、企業としての原則の両立について( ̄Д ̄)ノ
回りくどい言い方して長々書いちゃうのも悪い癖なのでサラッといいますv(。・ω・。)ィェィ♪
データ集めをひとりでやろうとするな!!しかし人に丸投げするな!!
ってことかな?
いえね、大きな組織・しっかりした組織で統計的な分析やデータ収集を専門とする部隊や担当者の人ならそれでいいんです(`・ω・´)ノ
でも問題は中小零細企業で部下を持つ人です。 .....φ(・ω・*)カキカキ
会社の規模が小さくなるほど人材は貴重です。そして、統計学に留まらず、ある分野で一定以上の能力がある人間は大半が努力し、新しいこと・難しいことに取り組んでいける人材と期待されることでしょう。
ところが統計学をある程度知ってる人はこれが魔法じゃないことも知ってます(*・ω・*)b♪
そして地道な努力を積み上げることができるタイプの人はデータの取り方が繁雑だと分析の信頼性を損なうことがあるのを懸念して自分でデータ収集に当たっちゃう人が多いように思うんですよね?
経験を養い、判断力や自信をつけるためには有効なことだと思うんですが、悲しいかな分析の計画を立案して実行していける時点で、小さなグループや班でのリーダーレベルだと思うんですよね?
そういう人が、n=50とかならまだしも100やら1000やらのデータ集めで何日も潰しちゃったら他の仕事の進行が遅れちゃうでしょ?
その人の指示で動いてる人たちは適当に自分で考えて仕事するかも知れないけど野放しに個々で動いては能率が上がらないこともしばしばあります(`・ω・´)ノ
組織とは、リーダーが練った計画やスケジュールに基づき、将来に向けて複数の人間が同じ方向に向かっていってなんぼです(*・ω・*)b♪
そして、その方向性に責任を持ち人を動かしていく側の人ほど報酬は高く、それに比べただ付き従う人たちの報酬は低いというのが現実( p′︵‵。)
気持ちのいい話ではありませんが、現実です。目を背けないでください。
企業とはあくまで商売する集団。お金稼いでなんぼ( ̄Д ̄)ノ
少ない投資で多くの成果(利益)を得るのが目的です。
分析にだってコストが掛かります。商品と違って値札がつかないだけです(*`σェ´*)フムフム
部下を持つ立場の人なら月給は部下と同じじゃないでしょう?
なら、その人が分析計画からデータ収集・分析までやった場合とデータ収集だけでも部下に任せた場合、どちらが低コストかは明白ですよね??
統計学の事情だけ言うとデータ分析の手法や何を分析したいかを明確にわかっている人(つまり計画を考えた人)がデータ収集に当たるのがベストです。
でも企業の事情で言うとそれを少しでも安くやってくれ。
それが終わったら間髪いれず次の計画を立案して掛かってくれ!!
ってとこですよね?
つまり及第点は・・・分析の手法やデータのとり方などをきちんと部下に教え、引き継いで、任せることです。
何も全く自分でやるなといってるんじゃありません。
まず最初は自分でやって、測定方法をきちんと作ってから引き継ぐとか、少し遠回りでも部下と測定のレベルあわせなどをして任せるといった事をすればいいんじゃないでしょうか?
そういうことを積み重ねていくとそのうちに部下も成長していろんな事を任せられる様になるし、データ収集してもらってる間に次の計画を考えることもできる様になり、組織としての活動スピードが速くなるはずです。
なんでこんなことを書くかって?
それは僕が今までそういうことをやってこなかったから(*・ω・*)b♪
そして管理職になって数年・・・部下が育っておりません。( ̄Д ̄)ノ
最近上司が実務を行うコストとかそういうことを自分の部署を後任に引き継ぐタイミングになってようやく真剣に意識しだしました。
僕が分析なんかを行うのに部下にデータ収集を積極的に任せたのは、自動化されて誰がやっても誤差の無いようなものばかり・・・。
ただ一人だけパートさんでどんな検査器でも僕とほとんど測定誤差の無い人が居ました。
その人には何度か大量のデータ収集を手伝ってもらいましたが、思い起こせばその時は非常にスムーズでした(*`σェ´*)フムフム
データを取ってもらう間に、いろいろ仮説を立てて考えられたし、分析結果が良かったらこう、わるかったらこうしようという作戦もあらかじめなんパターンか考えておけたからです。
時に考えが行き詰ったら、パートさんの測定してるのを後ろから見つめて、ハッと閃いて設備の仕組みをみてまたパートさんを見つめるなんて行動もできましたv(。・ω・。)ィェィ♪
そう考えると失敗を恐れて抱え込むより、人を信じて(信じられるだけの土台を一緒に作って)任せるってのはホント大事だと思います(*・ω・*)b♪
統計学だけではなく、専門分野に深く入り込むとその分野の原則みたいなものに縛られてしまいがちになります(*`σェ´*)
でもね、結局は仕事って商売でしょ?その分野もどこかでお金を稼ぐことにつながってるんだから、組織活動の原則もおろそかにしないよう、どこかで及第点を探してみることを忘れない様にしたいもんです(*・ω・*)b♪
以上、今日は僕の反省談を棚上げした身もフタも無い話でした 笑
(´∀`*)ノシ バイバイ
----------------------------------------
目次へ→
---------------------------------------
もともと、統計学の復習なんかから始まったこのブログも僕の意志の弱さから方向性を失いかけていますので、久々に路線を戻そうと思います ドモヽ(´Д` ) ( ´Д`)ノドモ
じゃあ何の話すんの?ってとこなんですが、端的、ミクロ的に言えばデータ収集の注意事項(`・ω・´)ノ
対極的、マクロ的に言えば統計的原則と組織活動、企業としての原則の両立について( ̄Д ̄)ノ
回りくどい言い方して長々書いちゃうのも悪い癖なのでサラッといいますv(。・ω・。)ィェィ♪
データ集めをひとりでやろうとするな!!しかし人に丸投げするな!!
ってことかな?
いえね、大きな組織・しっかりした組織で統計的な分析やデータ収集を専門とする部隊や担当者の人ならそれでいいんです(`・ω・´)ノ
でも問題は中小零細企業で部下を持つ人です。 .....φ(・ω・*)カキカキ
会社の規模が小さくなるほど人材は貴重です。そして、統計学に留まらず、ある分野で一定以上の能力がある人間は大半が努力し、新しいこと・難しいことに取り組んでいける人材と期待されることでしょう。
ところが統計学をある程度知ってる人はこれが魔法じゃないことも知ってます(*・ω・*)b♪
そして地道な努力を積み上げることができるタイプの人はデータの取り方が繁雑だと分析の信頼性を損なうことがあるのを懸念して自分でデータ収集に当たっちゃう人が多いように思うんですよね?
経験を養い、判断力や自信をつけるためには有効なことだと思うんですが、悲しいかな分析の計画を立案して実行していける時点で、小さなグループや班でのリーダーレベルだと思うんですよね?
そういう人が、n=50とかならまだしも100やら1000やらのデータ集めで何日も潰しちゃったら他の仕事の進行が遅れちゃうでしょ?
その人の指示で動いてる人たちは適当に自分で考えて仕事するかも知れないけど野放しに個々で動いては能率が上がらないこともしばしばあります(`・ω・´)ノ
組織とは、リーダーが練った計画やスケジュールに基づき、将来に向けて複数の人間が同じ方向に向かっていってなんぼです(*・ω・*)b♪
そして、その方向性に責任を持ち人を動かしていく側の人ほど報酬は高く、それに比べただ付き従う人たちの報酬は低いというのが現実( p′︵‵。)
気持ちのいい話ではありませんが、現実です。目を背けないでください。
企業とはあくまで商売する集団。お金稼いでなんぼ( ̄Д ̄)ノ
少ない投資で多くの成果(利益)を得るのが目的です。
分析にだってコストが掛かります。商品と違って値札がつかないだけです(*`σェ´*)フムフム
部下を持つ立場の人なら月給は部下と同じじゃないでしょう?
なら、その人が分析計画からデータ収集・分析までやった場合とデータ収集だけでも部下に任せた場合、どちらが低コストかは明白ですよね??
統計学の事情だけ言うとデータ分析の手法や何を分析したいかを明確にわかっている人(つまり計画を考えた人)がデータ収集に当たるのがベストです。
でも企業の事情で言うとそれを少しでも安くやってくれ。
それが終わったら間髪いれず次の計画を立案して掛かってくれ!!
ってとこですよね?
つまり及第点は・・・分析の手法やデータのとり方などをきちんと部下に教え、引き継いで、任せることです。
何も全く自分でやるなといってるんじゃありません。
まず最初は自分でやって、測定方法をきちんと作ってから引き継ぐとか、少し遠回りでも部下と測定のレベルあわせなどをして任せるといった事をすればいいんじゃないでしょうか?
そういうことを積み重ねていくとそのうちに部下も成長していろんな事を任せられる様になるし、データ収集してもらってる間に次の計画を考えることもできる様になり、組織としての活動スピードが速くなるはずです。
なんでこんなことを書くかって?
それは僕が今までそういうことをやってこなかったから(*・ω・*)b♪
そして管理職になって数年・・・部下が育っておりません。( ̄Д ̄)ノ
最近上司が実務を行うコストとかそういうことを自分の部署を後任に引き継ぐタイミングになってようやく真剣に意識しだしました。
僕が分析なんかを行うのに部下にデータ収集を積極的に任せたのは、自動化されて誰がやっても誤差の無いようなものばかり・・・。
ただ一人だけパートさんでどんな検査器でも僕とほとんど測定誤差の無い人が居ました。
その人には何度か大量のデータ収集を手伝ってもらいましたが、思い起こせばその時は非常にスムーズでした(*`σェ´*)フムフム
データを取ってもらう間に、いろいろ仮説を立てて考えられたし、分析結果が良かったらこう、わるかったらこうしようという作戦もあらかじめなんパターンか考えておけたからです。
時に考えが行き詰ったら、パートさんの測定してるのを後ろから見つめて、ハッと閃いて設備の仕組みをみてまたパートさんを見つめるなんて行動もできましたv(。・ω・。)ィェィ♪
そう考えると失敗を恐れて抱え込むより、人を信じて(信じられるだけの土台を一緒に作って)任せるってのはホント大事だと思います(*・ω・*)b♪
統計学だけではなく、専門分野に深く入り込むとその分野の原則みたいなものに縛られてしまいがちになります(*`σェ´*)
でもね、結局は仕事って商売でしょ?その分野もどこかでお金を稼ぐことにつながってるんだから、組織活動の原則もおろそかにしないよう、どこかで及第点を探してみることを忘れない様にしたいもんです(*・ω・*)b♪
以上、今日は僕の反省談を棚上げした身もフタも無い話でした 笑
(´∀`*)ノシ バイバイ
----------------------------------------
目次へ→
---------------------------------------
自由度って.....φ(・ω・*)カキカキ [統計学]
昨日は標準偏差に関するまとめ その1を書いたわけですが、今日コメントをいただいておりまして、自由度についてもちょっと詳しくとのリクエストでしたので、近々書いてみようと思います(*・ω・*)b♪
コメントをいただいた方は仕事上、統計分析をされる中堅社員の方だとのことで、そんな方に真剣に読んでいただけていると思うとうれし恥ずかしで身のしまる思いです(*`σェ´*)
自由度についてはどの書籍でもHPでも説明に苦労されている感じですね(`・ω・´)ノ
苦労というか、読んでて感じるのは自由度の意味をきちんと理解している人の大半は統計学の中~上級者クラスの人で説明も専門的なものが多いので難しいですね( p′︵‵。)
と言う僕もまだまだ勉強中の身なので、とりあえず自分なりに納得はしているけど今回のコメントを受けてすこし復習してみることにしました。
前に使っていた教科書や最近の新しいHPをチェックしてなんとなく僕なりの説明の仕方がイメージできてきたので、明日には下資料の作成に掛かりたいと思います.....φ(・ω・*)カキカキ
ちなみに今の僕の理解を簡単に言うと、自由度っていうのは他のデータによって確定されないデータ数のこと。平均がなければ、平均の元になってるデータはどのデータの影響も受けず、他のデータから推定することはできません。
でも仮に10個のデータの平均を算出しておいて、その後平均値はそのまま、データを一個だけ見えないようにしたところで、これは計算すれば導き出せます。(`・ω・´)ノ
つまり、残り9個のデータと平均により確定(推定というべき?)されてしまうデータがn数のうち1つある。
だからこれは自由度として扱っちゃだめ!!ということでn-1となる。
そして、10個のデータが母集団の全てのとき、(単に母集団の特徴を知りたいとき)は未知のデータはなく、個々のデータ達からみれば「いまさら平均がわかったから何??僕らは影響されませんよ??」って話ですよね?
でも10個のデータが母集団の全てではなかったとき、(未知の母集団の性質を推定するとき)は10個の平均値と母集団全体の平均値が同じと過程すると、平均値が算出されることで確定してくるデータが必ず一個出てきます。(`・ω・´)ノ
これがさっきの10個のデータのうち一個だけ見えなくした状態!!
そして統計学の用途としては大きく二つあって、前述の「データ数が母集団すべての場合、この特徴をひとつの数字で表すと??」って場合と今書いた「このデータから母集団の特徴をひとつの数字で推測すると??」って場合後者の元データが全く同じ場合、後者はあくまで「確率的(有意水準?%の精度で)にこうなるでしょう」って言い方になるので、出てくる数字にもハバを持たせる必要がありますから、n-1という自由度が使われます。(*`σェ´*)フムフム
ここまでが、今のところの僕の自由度に対する理解ですね(`・ω・´)ノ
これであーなるほどと思った方は機会があれば、自由度で悩んでる人に同じ説明をしてあげてください。
言ってる途中で「なんかシックリこないなぁ」って思ったらそれは今の僕と同じ現象ですv(。・ω・。)ィェィ♪
僕も今改めて書いてみてシックリきてません 笑
ということで冒頭に書いたように明日からもう少し掘り下げて調べつつ、下資料の作成に掛かっていこうと思います。.....φ(・ω・*)カキカキ
要するに・・・「本件については、もっと勉強して出直して参りたいと思います。今しばらくお時間をくださいm(__)m」
じゃあ書くなよって話ですよね?(((c=(゚ロ゚;qホワチャー
でもこの内容で考え方の大筋は間違ってないと思いますので、どうしても気になる方が調べたり、解釈するための取っ掛かりにでもなれればと思いましたのでそこはご容赦ください。m(__)m
ということで長々とわかる様なわからない説明にお付き合いいただき今日もありがとうございました。
(´∀`*)ノシ バイバイ
------------------------------------------
目次へ→
------------------------------------------
コメントをいただいた方は仕事上、統計分析をされる中堅社員の方だとのことで、そんな方に真剣に読んでいただけていると思うとうれし恥ずかしで身のしまる思いです(*`σェ´*)
自由度についてはどの書籍でもHPでも説明に苦労されている感じですね(`・ω・´)ノ
苦労というか、読んでて感じるのは自由度の意味をきちんと理解している人の大半は統計学の中~上級者クラスの人で説明も専門的なものが多いので難しいですね( p′︵‵。)
と言う僕もまだまだ勉強中の身なので、とりあえず自分なりに納得はしているけど今回のコメントを受けてすこし復習してみることにしました。
前に使っていた教科書や最近の新しいHPをチェックしてなんとなく僕なりの説明の仕方がイメージできてきたので、明日には下資料の作成に掛かりたいと思います.....φ(・ω・*)カキカキ
ちなみに今の僕の理解を簡単に言うと、自由度っていうのは他のデータによって確定されないデータ数のこと。平均がなければ、平均の元になってるデータはどのデータの影響も受けず、他のデータから推定することはできません。
でも仮に10個のデータの平均を算出しておいて、その後平均値はそのまま、データを一個だけ見えないようにしたところで、これは計算すれば導き出せます。(`・ω・´)ノ
つまり、残り9個のデータと平均により確定(推定というべき?)されてしまうデータがn数のうち1つある。
だからこれは自由度として扱っちゃだめ!!ということでn-1となる。
そして、10個のデータが母集団の全てのとき、(単に母集団の特徴を知りたいとき)は未知のデータはなく、個々のデータ達からみれば「いまさら平均がわかったから何??僕らは影響されませんよ??」って話ですよね?
でも10個のデータが母集団の全てではなかったとき、(未知の母集団の性質を推定するとき)は10個の平均値と母集団全体の平均値が同じと過程すると、平均値が算出されることで確定してくるデータが必ず一個出てきます。(`・ω・´)ノ
これがさっきの10個のデータのうち一個だけ見えなくした状態!!
そして統計学の用途としては大きく二つあって、前述の「データ数が母集団すべての場合、この特徴をひとつの数字で表すと??」って場合と今書いた「このデータから母集団の特徴をひとつの数字で推測すると??」って場合後者の元データが全く同じ場合、後者はあくまで「確率的(有意水準?%の精度で)にこうなるでしょう」って言い方になるので、出てくる数字にもハバを持たせる必要がありますから、n-1という自由度が使われます。(*`σェ´*)フムフム
ここまでが、今のところの僕の自由度に対する理解ですね(`・ω・´)ノ
これであーなるほどと思った方は機会があれば、自由度で悩んでる人に同じ説明をしてあげてください。
言ってる途中で「なんかシックリこないなぁ」って思ったらそれは今の僕と同じ現象ですv(。・ω・。)ィェィ♪
僕も今改めて書いてみてシックリきてません 笑
ということで冒頭に書いたように明日からもう少し掘り下げて調べつつ、下資料の作成に掛かっていこうと思います。.....φ(・ω・*)カキカキ
要するに・・・「本件については、もっと勉強して出直して参りたいと思います。今しばらくお時間をくださいm(__)m」
じゃあ書くなよって話ですよね?(((c=(゚ロ゚;qホワチャー
でもこの内容で考え方の大筋は間違ってないと思いますので、どうしても気になる方が調べたり、解釈するための取っ掛かりにでもなれればと思いましたのでそこはご容赦ください。m(__)m
ということで長々とわかる様なわからない説明にお付き合いいただき今日もありがとうございました。
(´∀`*)ノシ バイバイ
------------------------------------------
目次へ→
------------------------------------------
標準偏差のまとめ1 [統計学]
久々に統計学のお話(*・ω・*)b♪
やっとひとつのまとめです。+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
最初のころに似たような記事を書きましたが、エクセルでのまとめではなかったのでやり直し!!
これまで標準偏差について、書いてきましたが、そもそも標準偏差とはどう計算してるの?
ばらつきをあらわすってどうゆうこと??
って疑問を追及してみます。
↓こんなデータがあったとします
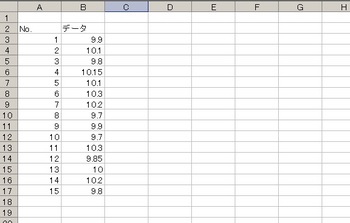
↓標準偏差を一発計算してみます。
エクセルで「=stdev(セル:セル)」が計算式です。
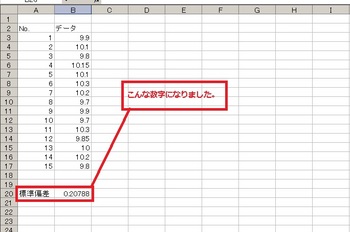
標準偏差はデータ全体のばらつきの程度をひとつの数字で表したものです。(`・ω・´)ノ
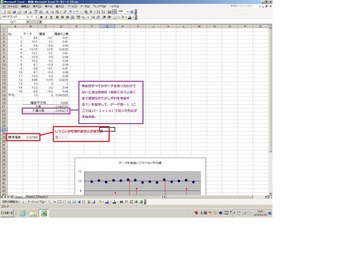
それってどうゆうこと??って所です。このデータをグラフ化したときのプロット(点)の広がりがばらつきです。
↓↓↓
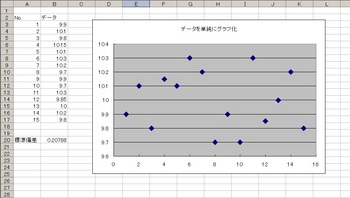
もう少しわかりやすくするためにこの15個のデータの平均値を求めてグラフに平均線を描いてみました。
↓↓エクセルでの平均を求める式は「=average(セル:セル)」です。
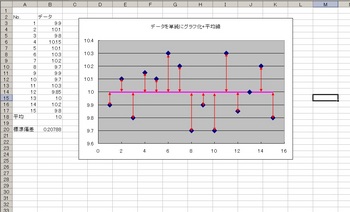
赤矢印で示した、ここのプロットと平均線との距離(差)がバラツキです(*`σェ´*)
これを「偏差」といいます。
とりあえず、これを数値として出してみますね。
個々のデータ-平均=偏差となります。
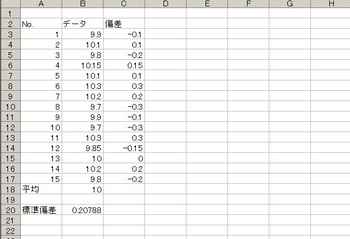
偏差が個々のデータのバラツキ度合いを示すなら、これを平均すりゃいいじゃん?+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
ってことで偏差の平均を求めてみました(´∀`*)ウフフ
↓↓↓
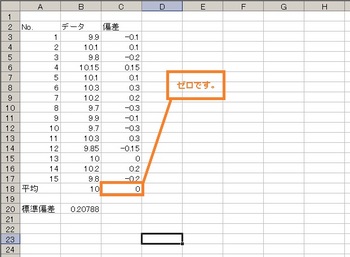
・・・|д・) ソォーッ… 0になりましたね・・・
そりゃそうですよね?平均とは全データの中心・・・そこからのズレを出して平均したら0になりますよね・・・。
+の数字と-の数字が等しくあるので相殺しちゃうんですよね( ̄Д ̄)ノ
ここで諦めなかった昔の人は偉いですよね~☆
じゃあ無理やり全部+の数字にしちゃえ!!! どうやって??
プラスの数字はそのままにしておきたい。マイナスはプラスにしたい・・・なら2乗しちゃえ!!!!!
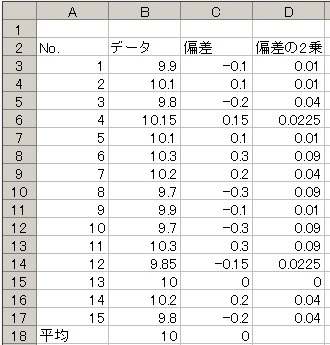
これで全部プラスの数値になった(´∀`*)ウフフ
さてこれを平均するためにまず合計をもとめましょう
合計の計算式は「=sum(セル:セル)」です。
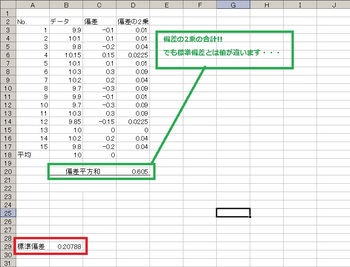
まだ標準偏差とは違う数字・・・( p′︵‵。) クヤシー
でもねこの数字もこれから活躍します(*・ω・*)b♪
この偏差の2乗の合計を「偏差平方和」と言います。ややこしい名前ですね?
ちょっと余談ですけど、 「㎡」この単位は平方メートルと読みますよね?長さ(メートル)×長さ(メートル)で㎡となりm(メートル)の右上にちっちゃい2が乗っかります。.....φ(・ω・*)カキカキ
ちっちゃい2が乗っかるのって2乗ってこと!つまり平方って2乗のことなんですよねv(。・ω・。)ィェィ♪
そして和は和、差、積、商って+、-、×、÷のこと。つまり偏差(の2乗)平方(を全て合計)和したものということでした~(*^ワ^*)
さて本題に戻って、偏差の2乗の平均を出したいんでしたね?
なので偏差平方和をデータ数=15で割ってみましょう(*・ω・*)b♪↓↓↓
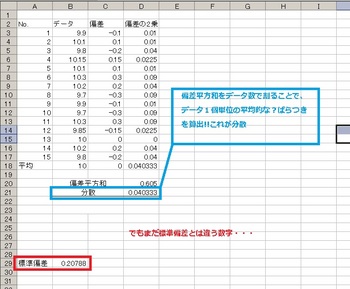
まだ標準偏差にはたどりつかない・・・( p′︵‵。) マダナノ?
でもこれも統計学では活躍する数字、「分散」といいます。分散分析に用います。(*・ω・*)b♪
というか製造業において、全ての商品のデータを取るなんてことはあまりありませんよね?
そんなときは、全データ数で割るのではなくて、「自由度」といってデータ数-1の数字で割り算したりするんです。(`・ω・´)ノ
自由度ってなに?なんで-1なの??って所は書くと長くなりそうなのでまた今度まとめることにしますね。
とにかくそういうことで自由度を加味して偏差平方和を割り算してみました。(*・ω・*)b♪
※ちょっと見えてるグラフは編集ミス・・・気にしないでください。
んでこれまた標準偏差とは違う数字・・・( p′︵‵。) モウヤダ・・・
でもこれも活躍する数字!!!「不偏分散」といいます。
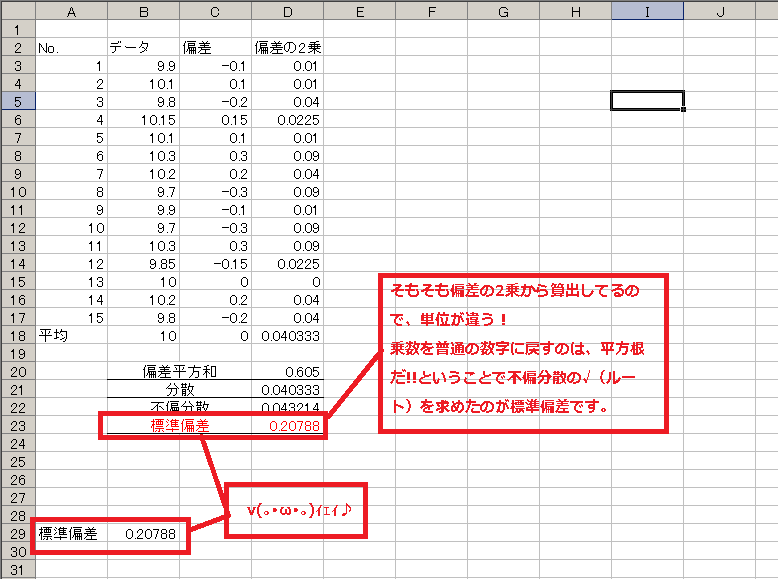
てかそもそも2乗してるから単位違うじゃん!!! mの寸法データだったら㎡になってんじゃん!!Σ( ̄□ ̄;)
2乗・・・乗数・・・元に戻すのはー・・・あー・・・平方根!!ルート!!! こんなやつ→√
ってことでとりあえず不偏分散の平方根を算出してみます。(`・ω・´)ノ
エクセルでの平方根は「=sqrt(セル)」です。
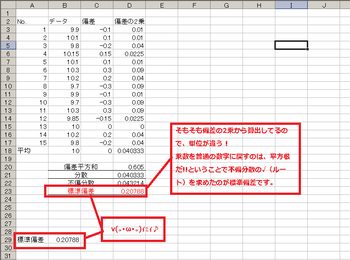
+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
ドンピシャです!!
つまり標準偏差とは、平均からの個々のデータのズレ=偏差をひとつの数字で表すためのもの。
その過程でじゃまな+や-の符号を排除するために2乗したりするので、平方根なんかも出てきますが、単純に狙いは、偏差を平均化したいだけだと思ってください(`・ω・´)ノ
偏差を出しただけでは、二つのデータ群のバラツキ度合いを比較したいとき、もしもデータが100個とかあれば比較が非常に大変ですよね?ならそれをひとつの数字で表せたほうが便利でしょ?
今日長々と書いたような計算は冒頭に書いたようにエクセルの計算式で一発計算!!PCが全部やってくれますv(。・ω・。)ィェィ♪
でもその計算の中身を知ってるのと知ってないのでは、得た結果に対する理解に雲泥の差ができてくると僕は思います。(*`σェ´*)
人によっては無駄だと思う方も居るかも知れませんが、教科書に当たり前にさらっと書いてあることでも、自分が普段良く使う会社の数値データなんかを使って実践してみてください。
そういやって体感して覚えたことは「記憶・暗記」でなく「理解」として頭に焼きつきます(*・ω・*)b♪
ちなみに番外変です(`・ω・´)ノ
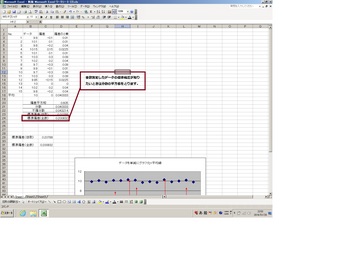
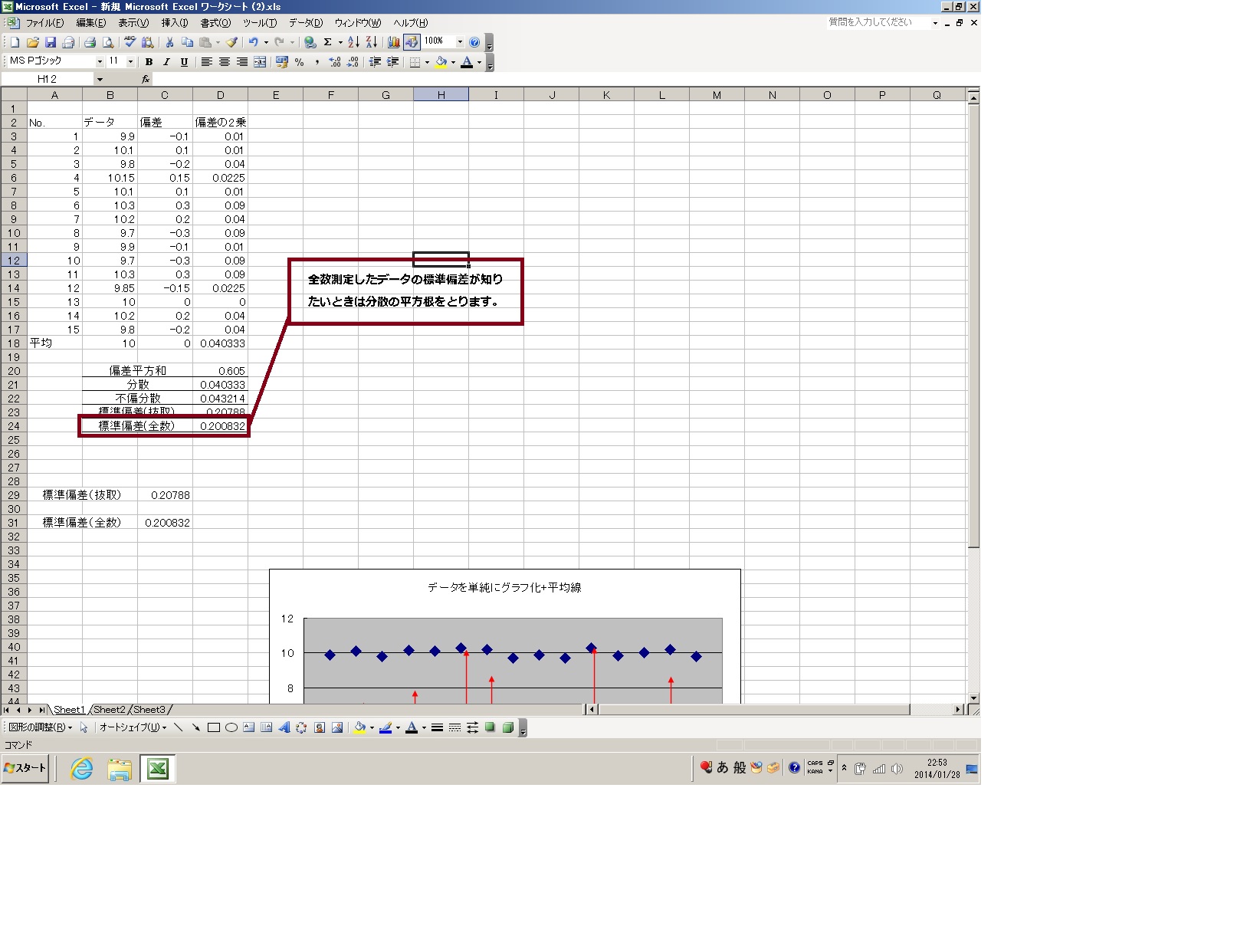
ここまでは母集団からの抜取データの標準偏差だったので、自由度を加味した不偏分散から標準偏差を出しました(*`σェ´*)フムフム
もし全数測定したデータの標準偏差を知りたいと言う場合には分散の平方根を取ってください。
計算式は「=STDEVP(セル:セル)」(全データの標準偏差)です。「P」がつくのをお忘れなく。(`・ω・´)ノ
ってことで最後に確認しておきましょう
さて、またしばらく時間がかかるとおもいますが、「標準偏差のまとめ2」も企画中です。(`・ω・´)ノ
これまでさらっと文章だけで語ってきた標準偏差の用途3σなどについてもうちょっとくわしく、
特にσ=64%で2σは何%でとかそういうところの確認をやってみようと思いますので興味ある方はお楽しみにどうぞv(。・ω・。)ィェィ♪
--------------------------------------------
目次へ→
--------------------------------------------
やっとひとつのまとめです。+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
最初のころに似たような記事を書きましたが、エクセルでのまとめではなかったのでやり直し!!
これまで標準偏差について、書いてきましたが、そもそも標準偏差とはどう計算してるの?
ばらつきをあらわすってどうゆうこと??
って疑問を追及してみます。
↓こんなデータがあったとします
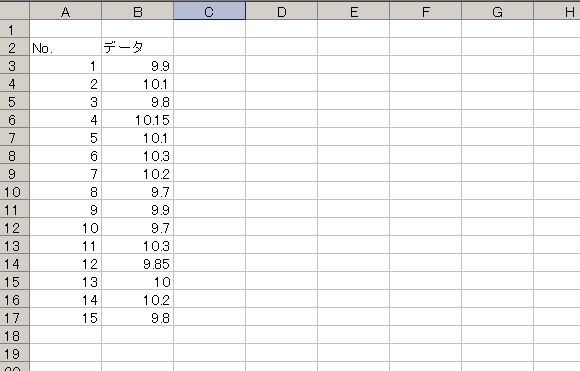
↓標準偏差を一発計算してみます。
エクセルで「=stdev(セル:セル)」が計算式です。
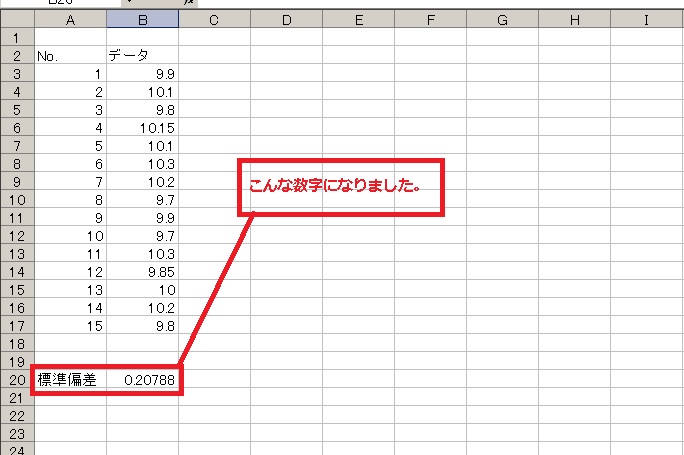
標準偏差はデータ全体のばらつきの程度をひとつの数字で表したものです。(`・ω・´)ノ
それってどうゆうこと??って所です。このデータをグラフ化したときのプロット(点)の広がりがばらつきです。
↓↓↓
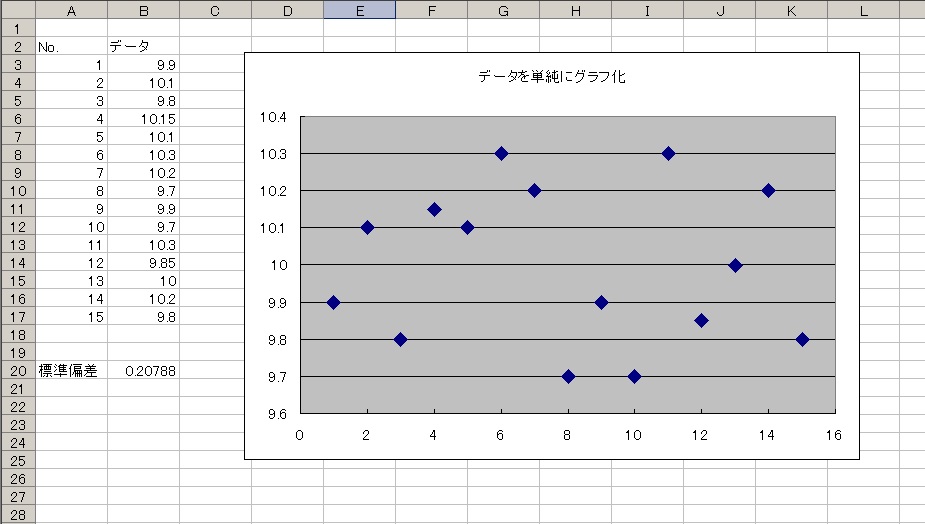
もう少しわかりやすくするためにこの15個のデータの平均値を求めてグラフに平均線を描いてみました。
↓↓エクセルでの平均を求める式は「=average(セル:セル)」です。
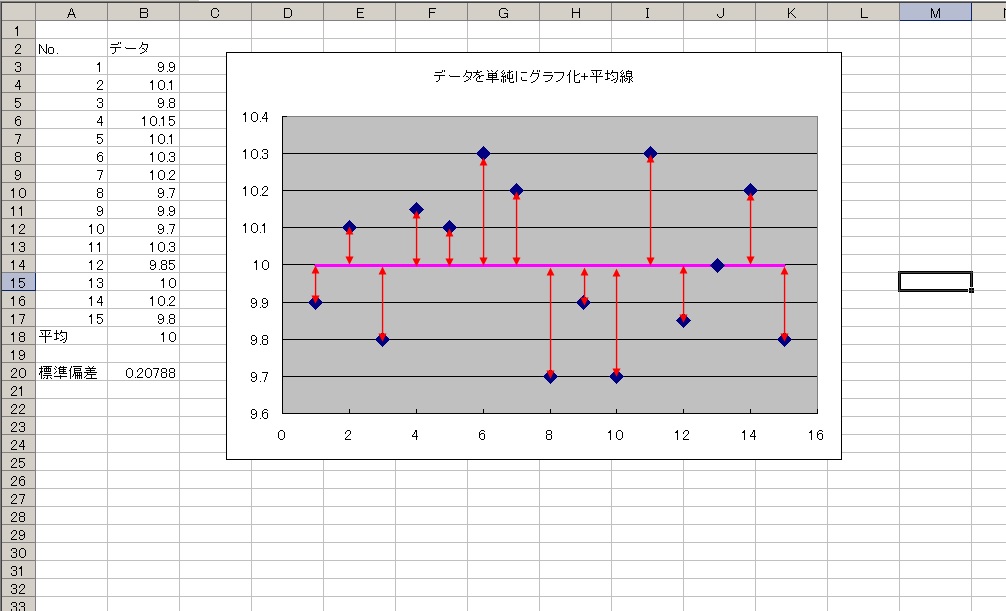
赤矢印で示した、ここのプロットと平均線との距離(差)がバラツキです(*`σェ´*)
これを「偏差」といいます。
とりあえず、これを数値として出してみますね。
個々のデータ-平均=偏差となります。

偏差が個々のデータのバラツキ度合いを示すなら、これを平均すりゃいいじゃん?+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
ってことで偏差の平均を求めてみました(´∀`*)ウフフ
↓↓↓
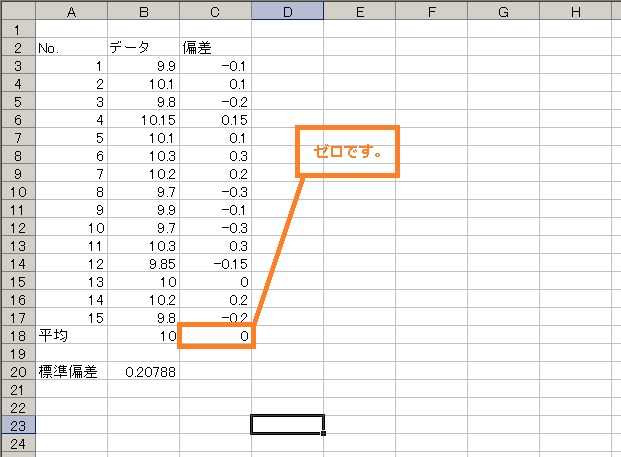
・・・|д・) ソォーッ… 0になりましたね・・・
そりゃそうですよね?平均とは全データの中心・・・そこからのズレを出して平均したら0になりますよね・・・。
+の数字と-の数字が等しくあるので相殺しちゃうんですよね( ̄Д ̄)ノ
ここで諦めなかった昔の人は偉いですよね~☆
じゃあ無理やり全部+の数字にしちゃえ!!! どうやって??
プラスの数字はそのままにしておきたい。マイナスはプラスにしたい・・・なら2乗しちゃえ!!!!!
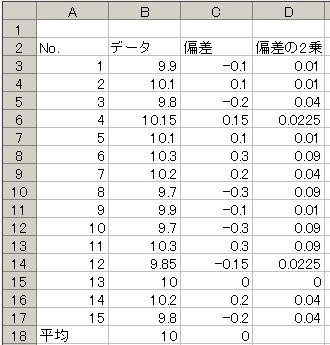
これで全部プラスの数値になった(´∀`*)ウフフ
さてこれを平均するためにまず合計をもとめましょう
合計の計算式は「=sum(セル:セル)」です。
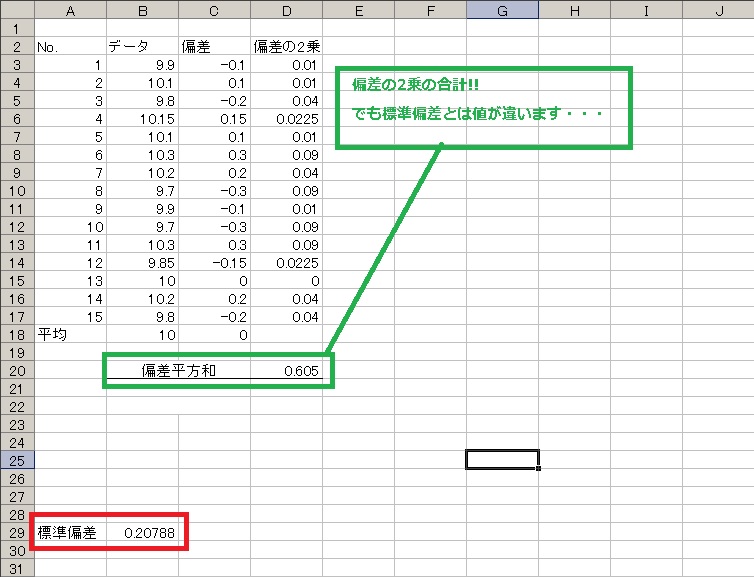
まだ標準偏差とは違う数字・・・( p′︵‵。) クヤシー
でもねこの数字もこれから活躍します(*・ω・*)b♪
この偏差の2乗の合計を「偏差平方和」と言います。ややこしい名前ですね?
ちょっと余談ですけど、 「㎡」この単位は平方メートルと読みますよね?長さ(メートル)×長さ(メートル)で㎡となりm(メートル)の右上にちっちゃい2が乗っかります。.....φ(・ω・*)カキカキ
ちっちゃい2が乗っかるのって2乗ってこと!つまり平方って2乗のことなんですよねv(。・ω・。)ィェィ♪
そして和は和、差、積、商って+、-、×、÷のこと。つまり偏差(の2乗)平方(を全て合計)和したものということでした~(*^ワ^*)
さて本題に戻って、偏差の2乗の平均を出したいんでしたね?
なので偏差平方和をデータ数=15で割ってみましょう(*・ω・*)b♪↓↓↓
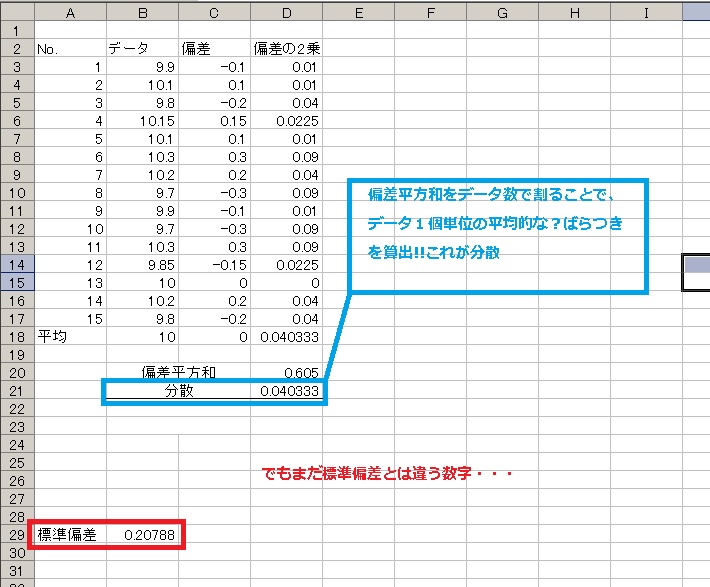
まだ標準偏差にはたどりつかない・・・( p′︵‵。) マダナノ?
でもこれも統計学では活躍する数字、「分散」といいます。分散分析に用います。(*・ω・*)b♪
というか製造業において、全ての商品のデータを取るなんてことはあまりありませんよね?
そんなときは、全データ数で割るのではなくて、「自由度」といってデータ数-1の数字で割り算したりするんです。(`・ω・´)ノ
自由度ってなに?なんで-1なの??って所は書くと長くなりそうなのでまた今度まとめることにしますね。
とにかくそういうことで自由度を加味して偏差平方和を割り算してみました。(*・ω・*)b♪

※ちょっと見えてるグラフは編集ミス・・・気にしないでください。
んでこれまた標準偏差とは違う数字・・・( p′︵‵。) モウヤダ・・・
でもこれも活躍する数字!!!「不偏分散」といいます。
てかそもそも2乗してるから単位違うじゃん!!! mの寸法データだったら㎡になってんじゃん!!Σ( ̄□ ̄;)
2乗・・・乗数・・・元に戻すのはー・・・あー・・・平方根!!ルート!!! こんなやつ→√
ってことでとりあえず不偏分散の平方根を算出してみます。(`・ω・´)ノ
エクセルでの平方根は「=sqrt(セル)」です。
+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
ドンピシャです!!
つまり標準偏差とは、平均からの個々のデータのズレ=偏差をひとつの数字で表すためのもの。
その過程でじゃまな+や-の符号を排除するために2乗したりするので、平方根なんかも出てきますが、単純に狙いは、偏差を平均化したいだけだと思ってください(`・ω・´)ノ
偏差を出しただけでは、二つのデータ群のバラツキ度合いを比較したいとき、もしもデータが100個とかあれば比較が非常に大変ですよね?ならそれをひとつの数字で表せたほうが便利でしょ?
今日長々と書いたような計算は冒頭に書いたようにエクセルの計算式で一発計算!!PCが全部やってくれますv(。・ω・。)ィェィ♪
でもその計算の中身を知ってるのと知ってないのでは、得た結果に対する理解に雲泥の差ができてくると僕は思います。(*`σェ´*)
人によっては無駄だと思う方も居るかも知れませんが、教科書に当たり前にさらっと書いてあることでも、自分が普段良く使う会社の数値データなんかを使って実践してみてください。
そういやって体感して覚えたことは「記憶・暗記」でなく「理解」として頭に焼きつきます(*・ω・*)b♪
ちなみに番外変です(`・ω・´)ノ
ここまでは母集団からの抜取データの標準偏差だったので、自由度を加味した不偏分散から標準偏差を出しました(*`σェ´*)フムフム
もし全数測定したデータの標準偏差を知りたいと言う場合には分散の平方根を取ってください。
計算式は「=STDEVP(セル:セル)」(全データの標準偏差)です。「P」がつくのをお忘れなく。(`・ω・´)ノ
ってことで最後に確認しておきましょう
さて、またしばらく時間がかかるとおもいますが、「標準偏差のまとめ2」も企画中です。(`・ω・´)ノ
これまでさらっと文章だけで語ってきた標準偏差の用途3σなどについてもうちょっとくわしく、
特にσ=64%で2σは何%でとかそういうところの確認をやってみようと思いますので興味ある方はお楽しみにどうぞv(。・ω・。)ィェィ♪
--------------------------------------------
目次へ→
--------------------------------------------
実験計画法とは? [統計学]
さてさて、今会社では僕のこれまで業務に使ってきたスキルを後任に引き継ぐための勉強会を定期的にやっています。((φ(・Д´・ *)ホォホォ
今回で一応は終わりなんですが、テーマは実験計画法について(*`σェ´*)フムフム
やり方までこってり説明するとちょっと大変なので、今回はどんなものなのかって所だけにしたいと思います(*・ω・*)b♪
実験計画法っていうと「これから実験するにあたっての計画を組み立てる手法?」って勘違いしちゃう人もいるかもですよね?
だって僕も最初そう思ってましたから 壁|ω・`)チラッ
実際は「実験により得たデータを分析するためのサンプリング(データ収集)の手法」でございます。
まぁサンプリングの方法を綿密に検討する事で実験の計画を組み立てる事にも繋がるから、最初に言った事もあながち間違いではないのか?
あまり追求すると言葉遊びになっちゃうのでやめましょうか(´・ω・`))))??))
この手法によって「ある結果に対して、どの要因が最も強く影響しているのか?」を知る事が出来ます。(`・ω・´)ノ
その他にも色んな応用もありますが・・・
R.A.フィッシャーって方が作り出した方法で、フィッシャーの三原則というものに基づいて行います。
1 反復
>実験ごとの偶然のバラツキ(誤差)の影響を除くために同条件で反復する。
同条件での加工や測定を繰り返す事で誤差の影響を少なくするんです。
2 局所管理
>影響を調べる要因以外の全ての要因を可能な限り一定にする。
事前に影響するであろう要因(因子)を全て抽出しておき、
一定にするための方法なんかもしっかりと検討。
3 無作為抽出(ランダムサンプリング)
>1・2でも一定に出来ない可能性のある因子の影響を少しでも受けにくくするため、
完全に無作為なサンプリングを行う。
例えば測定時間による環境の変化などが良く例にあがります。
完全にランダムにするには乱数表やサイコロなどの例があります。
僕の場合は、製品にナンバリングし、Excel上にそのNo.を入力。
No.の横に”=RAND()"で乱数を発生させオートフィルタで昇順に並び替え、
上から順にサンプリングします。
これらの手順に従いデータを分析する為には管理する条件や抽出方法なんかを事前にしっかりと検討しておく必要があります。
また、複数の要因を変化させて、その組み合わせによるデータの変化を意図的に作りだす事なんかもしますので、この組み合わせの取り方をきちんと考えれば結果的に実験回数や測定n数を減少させる事も可能なので、しばしば効率的な実験方法として採用される事もあります。(*・ω・*)b♪
実験計画法では主に抽出したデータを用いて分散分析を行います。
分散分析には結果に対しひとつの要因がどの程度影響するのかを判断する、一元配置法と複数の要因がる二元配置法(繰り返しのある/なしで手法が異なる)があります。
また、時には回帰分析(単回帰分析、重回帰分析がある)にも用いられます。
とまぁこんな所ですかね?
難しいワードが多くちょっと嫌になるかとも思いますが、標準偏差の仕組みなんかを理解できてればなんとかなると思います.....φ(・ω・*)カキカキ
とりあえず実験計画法については一旦こんな所で、またやり方や計算のサンプルはそのうち資料としてまとめて行きたいと思いますので、完成次第Upします(`・ω・´)ノ
それでは今日はこれにて⊂(・∀・)∂))バイバイ
---------------------------------------------
目次へ→
---------------------------------------------

")

今回で一応は終わりなんですが、テーマは実験計画法について(*`σェ´*)フムフム
やり方までこってり説明するとちょっと大変なので、今回はどんなものなのかって所だけにしたいと思います(*・ω・*)b♪
実験計画法っていうと「これから実験するにあたっての計画を組み立てる手法?」って勘違いしちゃう人もいるかもですよね?
だって僕も最初そう思ってましたから 壁|ω・`)チラッ
実際は「実験により得たデータを分析するためのサンプリング(データ収集)の手法」でございます。
まぁサンプリングの方法を綿密に検討する事で実験の計画を組み立てる事にも繋がるから、最初に言った事もあながち間違いではないのか?
あまり追求すると言葉遊びになっちゃうのでやめましょうか(´・ω・`))))??))
この手法によって「ある結果に対して、どの要因が最も強く影響しているのか?」を知る事が出来ます。(`・ω・´)ノ
その他にも色んな応用もありますが・・・
R.A.フィッシャーって方が作り出した方法で、フィッシャーの三原則というものに基づいて行います。
1 反復
>実験ごとの偶然のバラツキ(誤差)の影響を除くために同条件で反復する。
同条件での加工や測定を繰り返す事で誤差の影響を少なくするんです。
2 局所管理
>影響を調べる要因以外の全ての要因を可能な限り一定にする。
事前に影響するであろう要因(因子)を全て抽出しておき、
一定にするための方法なんかもしっかりと検討。
3 無作為抽出(ランダムサンプリング)
>1・2でも一定に出来ない可能性のある因子の影響を少しでも受けにくくするため、
完全に無作為なサンプリングを行う。
例えば測定時間による環境の変化などが良く例にあがります。
完全にランダムにするには乱数表やサイコロなどの例があります。
僕の場合は、製品にナンバリングし、Excel上にそのNo.を入力。
No.の横に”=RAND()"で乱数を発生させオートフィルタで昇順に並び替え、
上から順にサンプリングします。
これらの手順に従いデータを分析する為には管理する条件や抽出方法なんかを事前にしっかりと検討しておく必要があります。
また、複数の要因を変化させて、その組み合わせによるデータの変化を意図的に作りだす事なんかもしますので、この組み合わせの取り方をきちんと考えれば結果的に実験回数や測定n数を減少させる事も可能なので、しばしば効率的な実験方法として採用される事もあります。(*・ω・*)b♪
実験計画法では主に抽出したデータを用いて分散分析を行います。
分散分析には結果に対しひとつの要因がどの程度影響するのかを判断する、一元配置法と複数の要因がる二元配置法(繰り返しのある/なしで手法が異なる)があります。
また、時には回帰分析(単回帰分析、重回帰分析がある)にも用いられます。
とまぁこんな所ですかね?
難しいワードが多くちょっと嫌になるかとも思いますが、標準偏差の仕組みなんかを理解できてればなんとかなると思います.....φ(・ω・*)カキカキ
とりあえず実験計画法については一旦こんな所で、またやり方や計算のサンプルはそのうち資料としてまとめて行きたいと思いますので、完成次第Upします(`・ω・´)ノ
それでは今日はこれにて⊂(・∀・)∂))バイバイ
---------------------------------------------
目次へ→
---------------------------------------------
- 作者: 大村 平
- 出版社/メーカー: 日科技連出版社
- 発売日: 2013/01
- メディア: 単行本
図解入門 よくわかる最新実験計画法の基本と仕組み―実験の効率化とデータ解析の全手法を解説 (How‐nual Visual Guide Book)
- 作者: 森田 浩
- 出版社/メーカー: 秀和システム
- 発売日: 2010/11
- メディア: 単行本
やさしい実験計画法―統計学の初歩からパラメータ設計の考え方まで
- 作者: 高橋 信
- 出版社/メーカー: オーム社
- 発売日: 2009/08
- メディア: 単行本
業務における統計学の大切さv(。・ω・。)ィェィ♪ [統計学]
さて最近統計学についてあれやこれや書いてますけど、前にも書いたとおり、製造業で品質を管理する上で統計的手法は非常に有効です。
これまで標準偏差や工程能力指数についてあれやこれやと書いてきましたが、まだまだこれだけではありません。(`・ω・´)ノ
僕自身の仕事が製造業で製造業が好きなので記事はそっちのほうにかたよっちゃってますが、その他にも小売業(これは前にもABC分析について書きましたけど)やその他の職種でもたくさん使われています。.....φ(・ω・*)カキカキ
ひどい場合には、振り込め詐欺やチェーンメールの配信にも統計的分析が用いられています。Σ( ̄□ ̄;)
例えばチェーンメールを流したうち登録される確率とかですかね。
いまや良くも悪くも統計学は学者さんや研究者だけのものではなくなり、さまざまな分野で統計学は用いられています。
でもそもそも根本の話をして、統計学でなにをしろっての?( ̄Д ̄)ノ
ってこれまでそういうことに携わってこなかった人からしたら思いますよね?
今日はそこんとこに焦点を当てようと思います。v(。・ω・。)ィェィ♪
これはね、なにも統計学に興味を持ち始めたばかりのひとだけじゃなくて、今すでにデータの分析なんかを行っている人にとっても忘れてはいけない大切なこと|д・) ソォーッ…
それは統計学をもってデータを分析し、経営の戦略につなげたり、工程の管理の必要度合いを判断したりするここと(*・ω・*)b♪
データの分析はきちんとしなきゃなりません。でも目的はデータの分析じゃない。分析結果をもって何かを決める、判断する、考える。そのための根拠付けとして、信頼に足りるものこそが統計学なんです。(`・ω・´)ノ
例えば、コンビニで働いていたとします。( ̄Д ̄)ノ
24時間年中無休でどの商品が良く売れるかなんて見張ることは当然できないわけですが、闇雲に商品を入荷したって、商品の回転が遅くなったり廃棄品が増えてもうかりませんよね?
そこでレジの集計データを元にどの時間帯にどの商品が売れるのかを統計的に分析して、最適な入荷品目、数量を決めるわけです。(*・ω・*)b♪
でもそんなの本店や本社の事務処理部隊の仕事でしょって思われると思います(`・ω・´)ノ
おっしゃる通りでございます。m(__)m
大きな企業にはその為の部署なりシステムなりがあるでしょう。
でもね、統計学においてほんとに重要なのは分析するという行為や難しい式を解くことじゃなく、何を分析するかなんです。v(。・ω・。)ィェィ♪
商品の売り上げ数や在庫との兼ね合いはデータ化するシステムがあります。( ̄Д ̄)ノ
けどどの時間帯に女性客が多く、どの商品とどの商品を見比べているか?
何曜日に男性客が多く、何も買わずに帰る割合はどのくらいか?
そんなことはいまだ現場でしかわかりません。(*`σェ´*)フムフム
製造業もしかり、サービス業もしかりです。(*・ω・*)b♪
いつだかアメリカで監視カメラの映像が通行人の男女、服装から趣味趣向までを読み取るシステムを開発したとかしてないとかニュースがありましたけど、そんなものが一般企業に導入されるのはまだまだ先でしょう。
そんなシステムにしたって、「このデータを集めてシステムに分析させよう」って決めるのは結局人なんですよ(*`σェ´*)
自身が統計学ができなくたっていいんです。(`・ω・´)ノ
統計学でもって何ができるかを知っておいて、こんなデータ分析できませんか?
結果どうでした?やっぱり?じゃあこうしましょ??って提案できるだけでも仕事のうえでの評価は全然ちがうでしょう。
自身で分析までできて対応案の提案までできればもっといいです。v(。・ω・。)ィェィ♪
いくらたくさんのデータを集めても、それを何に使うか知らなければ無意味な仕事です。(`・ω・´)ノ
そんなの楽しくないでしょ?
データの使い道を知ってても、眺めてるだけでは答えはでませんよね?
それも楽しくないというか辛いだけですよね?
僕はね、どうせなら楽しく仕事したいです(*・ω・*)b♪ 仕事した限りは認められたいです(*`σェ´*)
認められたのなら給料上げてほしいですv(。・ω・。)ィェィ♪
僕にとって統計学とは学問というよりは、機械をいじるときのドライバーやレンチと一緒。
目的を達成するためのツールのひとつです。(`・ω・´)ノ
ツール(道具)を使えば当然ながらきちんとした仕事ができますよね?
そして使わないより使ったほうが、作業は楽です。
でもね工具もそうですが事前に使い方を知ってないと役に立たないし、道具の使い方だけ知ってても、今自分が触ってる機械がなんなのか?エンジンなの?フレームなの?
このネジは固定用だから思いっきり締めたほうがいいの?
なんかの調節ネジだから締めすぎるとダメなの?
このあたりわかってないと後で悲惨なことになりますよね?統計学も同じです。(*・ω・*)b♪
でもね、難しいことじゃありません。v(。・ω・。)ィェィ♪
いやホントは難しいけどそこはパソコンがやってくれます。(*・ω・*)b♪
だから、僕らは統計学のいろんな分析手法の意味と何に使うのかをさえしっかり理解すればいいんです。
僕が駆け出しのころに買って、いまだに時々参考にするのが、「ハンバーガーショップで学ぶ統計学」って本です。(`・ω・´)ノ
身近なことを例に挙げてわかりやすく統計学を解説してくれてます。(*・ω・*)b♪
平均の信頼区間とかそんなのは使う機会も少ないですが、まずは用語や考え方に慣れたいって方にはぜひお勧めの一冊です。+。:.゚(*゚Д゚*)キタコレ゚.:。+゚
興味があれば一度ご購読ください。m(__)m
-----------------------------------
目次へ→
----------------------------------
")
- 作者: 向後 千春
- 出版社/メーカー: 技術評論社
- 発売日: 2007/09/07
- メディア: 単行本(ソフトカバー)
では本日はこれにて(´∀`*)ノシ バイバイ



